第0关 print()函数与变量 1、print()函数 1.1、打印函数 1.2、引号 2、转义字符
转义字符
意义
\a
响铃
\b
退格
\f
换页
\n
换行
\r
回车
\t
水平制表
\v
垂直制表
\\
代表一个反斜杠
\‘
代表一个单引号字符
\‘
代表一个双引号字符
?
代表一个问好
\o
空字符
\ddd
1到3位八进制所代表的任意字符
\xhh
1到2位十六进制所代表的任意字符
3、变量和赋值 3.1、变量命名规范
1、只能是一个词
第1关 数据类型与转换 1、数据类型 字符串str 用引号括起来的文本
整数int 没有小数点的数字
算术运算符
运算符
表示
例子
+
加
2+1=3
-
减
2-1=1
*
乘
2*3=6
/
除
6/3=2
%
取模-返回除法的余数
5/2=1
**
幂-返回x的y次幂
2**3=6
//
取整除-返回商的整数部分
11//2=5
简单运算优先级口诀 从左到右顺着来,括号里的优先算,乘除排在加减前。
浮点数float 带小数点的数字
2、数据拼接 查询数据类型 3、数据转换 str() 将其他数据类型转成字符串
int() 将其他数据类型转成整数
float() 将其他数据类型转成浮点数
第2关 条件判断与条件嵌套 1、条件判断 单向判断if
如果……就……
双向判断if…else…
如果不满足if条件,就执行else下的命令
多向判断if…elif…else…
如果不满足if的条件,就判断是否满足elif下的命令,满足执行,不满足执行else下的命令
2、if嵌套
根据缩进判断层级
3、如何写嵌套代码 扒洋葱式写法
1、写基础条件代码
收集信息需要在终端区输入
input()函数的结果必须赋值
返回类型必须为字符串
想要整数,源头转换
第4关 列表和字典 1、列表 什么是列表 中括号括起来的
从列表提取单个元素 从列表提取多个元素 索引取值
左右空,取到头,左要取,右不取
给列表增加/删除元素 增加 append()
它的作用是给列表添加元素,默认是会添加到列表末尾
删除 del()
del删除就是直接删除了没办法赋值
删除多个 索引取值
移除列表中的最后那个元素 pop()
pop函数删除的内容,是可以给变量赋值的,也就是说他有返回值
1 2 3 4 5 6 7 8 9 students = ['小明' , '小红' , '小刚' ] for i in range (3 ): student1 = students.pop(0 ) students.append(student1) print (students)
例子: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 s = ['柯佳嬿' , '许光汉' , '施柏宇' , '颜毓麟' , '林鹤轩' , '张翰' ] print (len (s)) print (type (s)) print (s[3 ]) print (s[-3 ]) list1 = [91 , 95 , 97 , 99 ] list2 = [92 , 93 , 96 , 98 ] list3 = list1+list2 print (list3)list1.extend(list2) print (list1)a = [91 , 95 , 97 , 99 , 92 , 93 , 96 , 98 ] a.sort() print (a)b = [91 , 95 , 97 , 99 , 92 , 93 , 96 , 98 ] b.sort(reverse=True ) print (b)c = [91 , 95 , 97 , 99 , 92 , 93 , 96 , 98 ] c.reverse() print (c)
2、数据类型:字典 什么是字典
元素是键值对。
1 scores = {'小明' :95 ,'小红' :90 ,'小刚' :90 }
长度函数 len()
取值 给字典增加/删除元素 增加
字典名[键] = 值
删除
del 字典名[键]
1 2 3 4 5 6 7 8 9 scores = {'小明' : 95 , '小红' : 90 , '小刚' : 90 } print (scores['小明' ]) scores['小红' ] = 88 print (scores['小红' ])scores['小北' ] = 98 print (scores)
3、列表和字典的异同 列表和字典的不同点
列表有序,要用偏移量定位;字典无序,便通过唯一的键来取值。
列表和字典的相同点
修改元素用赋值。
4、嵌套 1 2 3 4 5 6 7 8 9 10 11 12 13 students = { '第一组' :['小明' ,'小红' ,'小刚' ,'小美' ], '第二组' :['小强' ,'小兰' ,'小伟' ,'小芳' ] } print (students['第一组' ][3 ])scores = [ {'小明' :95 ,'小红' :90 ,'小刚' :100 ,'小美' :85 }, {'小强' :99 ,'小兰' :89 ,'小伟' :93 ,'小芳' :88 } ] print (scores[1 ]['小强' ])
5. 元祖(tuple)
元组的写法是将数据放在小括号()中,它的用法和列表用法类似,主要区别在于列表中的元素可以随时修改,但元组中的元素不可更改。
1 2 3 4 list2 = [('A' , 'B' ), ('C' , 'D' ), ('E' , 'F' )] print (list2[1 ][1 ])
以上几种关于收纳的数据类型,最常用的还是列表 ,而对偏移量 和切片 的使用是写算法非常重要的技能 。
第5关 for循环和while循环 1、for…in…循环语句
for循环的3个要点即是:
1.1、for循环:空房间
空房间的学名叫【元素】(item),你可以把它当成是一个变量。
1.2、for循环:一群排队办业务的人
字典、列表、字符串。
1.3、range()函数
可以生成一个【取头不取尾】的整数序列。
1 2 3 4 range (a,b,c)a:计数从a开始,不填时,默认从0 开始 b:计数到b结束,但不包括b c:计数的间隔,不填时默认为1
1.4、for循环:办事流程
“办事流程”的学名是【for子句】。格式是【冒号】后另起一行,【缩进】写命令。
2、while循环
在一定的条件下”,“按照流程办事。
2.1、while循环:放行条件
while在英文中表示“当”,while后面跟的是一个条件。当条件被满足时,就会循环执行while内部的代码(while子句)。
2.2、while循环:办事流程
while循环,在满足条件的时候,会一轮又一轮地循环执行代码。
3、两种循环对比
for循环和whlie循环最大的区别在于【循环的工作量是否确定】,for循环就像空房间依次办理业务,直到把【所有工作做完】才下班。但while循环就像哨卡放行,【满足条件就一直工作】,直到不满足条件就关闭哨卡。
第6关 布尔值和四种语句 1、用数据做判断:布尔值
用数据做逻辑判断的过程叫做【布尔运算】
1.1、两个数值做比较 比较运算符
名称
运算符
等于
==
不等于
!=
大于
>
小于
<
大于等于
>=
小于等于
<=
1.2、直接用数值做运算 真假判断
假的
其他都是真的
False
True
0
(任意整数和任意浮点数)
‘’(空字符串)
(字符串)
[] (空列表)
[1,2,3]
{} (空字典)
{1:’i’, 2:’d’}
None
1.3、布尔值之间的运算 and、or、not、in、not in五种运算
and
条件
返回值
true and true
为真
true and false
为假
false and true
为假
false and false
为假
or
条件
返回值
true or true
为真
true or false
为真
false or true
为真
false or false
为假
not
条件
返回值
not true
为假
not false
为真
in
判断一个元素是否在一堆数据之中。
not in
判断一个元素不在一堆数据之中。
2、四种新的语句 2.1、break语句
if...break的意思是如果满足了某一个条件,就提前结束循环。记住,这个只能在循环内部使用。
1 2 3 4 5 6 7 8 9 10 11 for ...in ...: ... if ...: break while ...(条件): ... if ...: break
2.2、continue语句
continue的意思是“继续”。这个子句也是在循环内部使用的。当某个条件被满足的时候,触发continue语句,将跳过之后的代码,直接回到循环的开始。
1 2 3 4 5 6 7 8 9 10 11 12 13 for ...in ...: ... if ...: continue ... while ...(条件): ... if ...: continue ...
2.3、pass语句
pass语句就非常简单了,它的英文意思是“跳过”。
2.4、else语句
最后一种else语句,我们在条件判断语句见过【else】,其实,else不但可以和if配合使用,它还能跟for循环和while循环配合使用。
1 2 3 4 while ...(条件): ... else : ...
2.5、循环小练习 猜大小游戏
1.一个人在心里想好一个数————这个数字是提前准备好的,可以设置一个变量来保存这个数字。我就设置我的数字为24。if...else...写一个条件判断。
第7关 项目实操:PK小游戏(1) 完成一个项目的流程
1、明确项目目标
1、明确项目目标
明确项目目标,是指我们希望程序达成什么目的,实现什么功能,从而帮我们将项目拆解成不同的单元;而一个妥当的拆解方案,难度适度递增,能帮我们逐步顺利执行,最终完成项目。这三个步骤可以说是环环相扣的。
2、分析过程,拆解项目
版本1:规定双方角色属性,战斗时人为计算扣血量 ,并打印出战斗过程。自动计算扣血量 ,并优化显示战斗过程的代码。
3、逐步执行,代码实现 3.1、版本1.0:自定属性,人工PK 基础元素
1、要有玩家、敌人
操作流程 1 2 3 4 5 6 st=>start: 显示玩家和敌人的属性 pk=>operation: PK过程展示双方血量变化 en=>end: 显示PK结果 st->pk->en
我们从第1步开始:设定【玩家】和【敌人】的属性,即【血量】和【攻击】。
1 2 print ('【玩家】血量:100 攻击:50' ) print ('【敌人】血量:100 攻击:30' )
第2步:手动计算攻击一次,双方各自所剩的血量。
1 2 print ('你发起了攻击,【敌人】剩余血量50' ) print ('敌人向你发起了攻击,【玩家】剩余血量70' )
第3步:继续做人工计算:算一算,玩家攻击2次敌人,敌人的血量就等于0了,这时候可以结束战斗,打印游戏结果。
1 2 3 4 print ('你发起了攻击,【敌人】剩余血量0' ) print ('敌人向你发起了攻击,【玩家】剩余血量40' )print ('敌人死翘翘了,你赢了!' )
三段拼接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 print ('【玩家】\n血量:100\n攻击:50' ) print ('------------------------' ) print ('【敌人】\n血量:100\n攻击:30' )print ('------------------------' )print ('你发起了攻击,【敌人】剩余血量50' ) print ('敌人向你发起了攻击,【玩家】剩余血量70' ) print ('------------------------' )print ('你发起了攻击,【敌人】剩余血量0' ) print ('敌人向你发起了攻击,【玩家】剩余血量40' )print ('-----------------------' )print ('敌人死翘翘了,你赢了!' )
增加时间模块
1 2 3 4 import time time.sleep(secs)
版本1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import time print ('【玩家】\n血量:100\n攻击:50' ) print ('------------------------' ) time.sleep(1.5 ) print ('【敌人】\n血量:100\n攻击:30' )print ('------------------------' )time.sleep(1.5 ) print ('你发起了攻击,【敌人】剩余血量50' ) print ('敌人向你发起了攻击,【玩家】剩余血量70' ) print ('------------------------' )time.sleep(1.5 ) print ('你发起了攻击,【敌人】剩余血量0' ) print ('敌人向你发起了攻击,【玩家】剩余血量40' )print ('-----------------------' )time.sleep(1.5 ) print ('敌人死翘翘了,你赢了!' )
3.2、版本2.0:随机属性,自动PK 操作流程
1 2 3 4 5 6 st=>start: 随机生成玩家和敌人的属性 pk=>operation: 显示玩家和敌人的属性 en=>end: PK过程展示自动攻击和扣血 st->pk->en
调用随机数
1 2 3 4 5 import random a = random.randint(1 ,100 ) print (a)
显示属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import timeimport randomplayer_life = random.randint(100 ,150 ) player_attack = random.randint(30 ,50 ) enemy_life = random.randint(100 ,150 ) enemy_attack = random.randint(30 ,50 ) print ('【玩家】\n' +'血量:' +str (player_life)+'\n攻击:' +str (player_attack))print ('------------------------' )time.sleep(1 ) print ('【敌人】\n' +'血量:' +str (enemy_life)+'\n攻击:' +str (enemy_attack))print ('------------------------' )
自动战斗
循环条件
如果双方血量都大于0,战斗会一直持续。
1 2 while (player_life >= 0 ) and (enemy_life >= 0 ):
循环内容
其中【敌人】剩余血量=敌人当前血量-玩家攻击,【玩家】剩余血量=玩家当前血量-敌人攻击。
1 2 3 print ('你发起了攻击,【敌人】剩余血量xxx' ) print ('敌人向你发起了攻击,【玩家】剩余血量xxx' ) print ('------------------------' )
重新赋值血量
1 2 3 player_life = player_life - enemy_attack enemy_life = enemy_life - player_attack
合并
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import time,randomplayer_life = random.randint(100 ,150 ) player_attack = random.randint(30 ,50 ) enemy_life = random.randint(100 ,150 ) enemy_attack = random.randint(30 ,50 ) print ('【玩家】\n' +'血量:' +str (player_life)+'\n攻击:' +str (player_attack))print ('------------------------' )time.sleep(1 ) print ('【敌人】\n' +'血量:' +str (enemy_life)+'\n攻击:' +str (enemy_attack))print ('------------------------' )time.sleep(1 ) while (player_life >0 ) and (enemy_life > 0 ): player_life = player_life - enemy_attack enemy_life = enemy_life - player_attack
版本2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import time,randomplayer_life = random.randint(100 ,150 ) player_attack = random.randint(30 ,50 ) enemy_life = random.randint(100 ,150 ) enemy_attack = random.randint(30 ,50 ) print ('【玩家】\n' +'血量:' +str (player_life)+'\n攻击:' +str (player_attack))print ('------------------------' )time.sleep(1 ) print ('【敌人】\n' +'血量:' +str (enemy_life)+'\n攻击:' +str (enemy_attack))print ('------------------------' )time.sleep(1 ) while (player_life >0 ) and (enemy_life > 0 ): player_life = player_life - enemy_attack enemy_life = enemy_life - player_attack print ('你发起了攻击,【敌人】剩余血量' +str (enemy_life)) print ('敌人向你发起了攻击,【玩家】剩余血量' +str (player_life)) print ('------------------------' ) time.sleep(1.5 )
3.3、版本3.0:打印战果,三局两胜
增加的功能是:1.打印战果:每局战斗后,根据胜负平的结果打印出不同的提示;2.三局两胜:双方战斗三局,胜率高的为最终赢家。
1 2 3 4 5 6 7 8 9 10 11 12 st=>start: 游戏开始 sj=>operation: 随机生成属性 xs=>operation: 显示属性 pk=>operation: PK过程展示 dj=>condition: 输出单局结果 jg=>operation: 输出三局两胜结果 en=>end: 游戏结束 st->sj->xs->pk->dj dj(no)->sj dj(yes)->jg->en
胜利的条件判断
1 2 if player_life > 0 and enemy_life <= 0 : print ('敌人死翘翘了,你赢了' )
单局
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import time,randomplayer_life = random.randint(100 ,150 ) player_attack = random.randint(30 ,50 ) enemy_life = random.randint(100 ,150 ) enemy_attack = random.randint(30 ,50 ) print ('【玩家】\n' +'血量:' +str (player_life)+'\n攻击:' +str (player_attack))print ('------------------------' )time.sleep(1 ) print ('【敌人】\n' +'血量:' +str (enemy_life)+'\n攻击:' +str (enemy_attack))print ('------------------------' )time.sleep(1 ) while player_life > 0 and enemy_life > 0 : player_life = player_life - enemy_attack enemy_life = enemy_life - player_attack print ('你发起了攻击,【敌人】剩余血量' +str (enemy_life)) print ('敌人向你发起了攻击,【玩家】剩余血量' +str (player_life)) print ('-----------------------' ) time.sleep(1.5 ) if player_life > 0 and enemy_life <= 0 : print ('敌人死翘翘了,你赢了' ) elif player_life <= 0 and enemy_life > 0 : print ('悲催,敌人把你干掉了!' ) else : print ('哎呀,你和敌人同归于尽了!' )
三局两胜
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import time,randomfor i in range (1 ,4 ): time.sleep(1.5 ) print (' \n——————现在是第' +str (i)+'局,ready go!——————' ) player_life = random.randint(100 ,150 ) player_attack = random.randint(30 ,50 ) enemy_life = random.randint(100 ,150 ) enemy_attack = random.randint(30 ,50 ) print ('【玩家】\n' +'血量:' +str (player_life)+'\n攻击:' +str (player_attack)) print ('------------------------' ) time.sleep(1 ) print ('【敌人】\n' +'血量:' +str (enemy_life)+'\n攻击:' +str (enemy_attack)) print ('------------------------' ) time.sleep(1 ) while player_life > 0 and enemy_life > 0 : player_life = player_life - enemy_attack enemy_life = enemy_life - player_attack print ('你发起了攻击,【敌人】剩余血量' +str (enemy_life)) print ('敌人向你发起了攻击,【玩家】剩余血量' +str (player_life)) print ('-----------------------' ) time.sleep(1.5 ) if player_life > 0 and enemy_life <= 0 : print ('敌人死翘翘了,你赢了' ) elif player_life <= 0 and enemy_life > 0 : print ('悲催,敌人把你干掉了!' ) else : print ('哎呀,你和敌人同归于尽了!' )
统计结果
空记分板
1 2 3 4 player_victory = 0 enemy_victory = 0
记分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 player_victory = 0 enemy_victory = 0 if player_life > 0 and enemy_life <= 0 : player_victory = player_victory + 1 print ('敌人死翘翘了,你赢了!' ) elif player_life <= 0 and enemy_life > 0 : enemy_victory = enemy_victory + 1 print ('悲催,敌人把你干掉了!' ) else : print ('哎呀,你和敌人同归于尽了!' ) player_victory = 0 enemy_victory = 0 if player_life > 0 and enemy_life <= 0 : player_victory += 1 print ('敌人死翘翘了,你赢了!' ) elif player_life <= 0 and enemy_life > 0 : enemy_victory += 1 print ('悲催,敌人把你干掉了!' ) else : print ('哎呀,你和敌人同归于尽了!' )
版本3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import time,randomplayer_victory = 0 enemy_victory = 0 for i in range (1 ,4 ): time.sleep(2 ) print (' \n——————现在是第' +str (i)+'局——————' ) player_life = random.randint(100 ,150 ) player_attack = random.randint(30 ,50 ) enemy_life = random.randint(100 ,150 ) enemy_attack = random.randint(30 ,50 ) print ('【玩家】\n' +'血量:' +str (player_life)+'\n攻击:' +str (player_attack)) print ('------------------------' ) time.sleep(1 ) print ('【敌人】\n' +'血量:' +str (enemy_life)+'\n攻击:' +str (enemy_attack)) print ('------------------------' ) time.sleep(1 ) while player_life > 0 and enemy_life > 0 : player_life = player_life - enemy_attack enemy_life = enemy_life - player_attack print ('你发起了攻击,【敌人】剩余血量' +str (enemy_life)) print ('敌人向你发起了攻击,【玩家】剩余血量' +str (player_life)) print ('-----------------------' ) time.sleep(1.5 ) if player_life > 0 and enemy_life <= 0 : player_victory += 1 print ('敌人死翘翘了,你赢了!' ) elif player_life <= 0 and enemy_life > 0 : enemy_victory += 1 print ('悲催,敌人把你干掉了!' ) else : print ('哎呀,你和敌人同归于尽了!' ) if player_victory > enemy_victory : time.sleep(1 ) print ('【最终结果:你赢了!】' ) elif enemy_victory > player_victory: print ('【最终结果:你输了!】' ) else : print ('【最终结果:平局!】' )
格式化字符串
格式符+类型码
含义
%s
字符串显示
%f
浮点数显示
%d
整数显示
优化版
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import timeimport randomplayer_victory = 0 enemy_victory = 0 for i in range (1 ,4 ): time.sleep(1.5 ) print (' \n——————现在是第 %s 局——————' % i) player_life = random.randint(100 ,150 ) player_attack = random.randint(30 ,50 ) enemy_life = random.randint(100 ,150 ) enemy_attack = random.randint(30 ,50 ) print ('【玩家】\n血量:%s\n攻击:%s' % (player_life,player_attack)) print ('------------------------' ) time.sleep(1 ) print ('【敌人】\n血量:%s\n攻击:%s' % (enemy_life,enemy_attack)) print ('-----------------------' ) time.sleep(1 ) while player_life > 0 and enemy_life > 0 : player_life = player_life - enemy_attack enemy_life = enemy_life - player_attack print ('你发起了攻击,【敌人】剩余血量%s' % enemy_life) print ('敌人向你发起了攻击,【玩家】的血量剩余%s' % player_life) print ('-----------------------' ) time.sleep(1.2 ) if player_life > 0 and enemy_life <= 0 : player_victory += 1 print ('敌人死翘翘了,你赢了!' ) elif player_life <= 0 and enemy_life > 0 : enemy_victory += 1 print ('悲催,敌人把你干掉了!' ) else : print ('哎呀,你和敌人同归于尽了!' ) if player_victory > enemy_victory : time.sleep(1 ) print ('\n【最终结果:你赢了!】' ) elif enemy_victory > player_victory: print ('\n【最终结果:你输了!】' ) else : print ('\n【最终结果:平局!】' )
基本逻辑
小游戏:两个角色互相打斗 打斗到死 游戏结束
1、本节课利用到的模块 import random:随机 本节课利用到它的一个小功能,随机整数,比如random.randint(取数区间),会随机取整 import time: time sleep(间隔时间/秒),print消息之间的间隔时间 2、游戏的基本逻辑 ①两个人打架,每个人有两个属性,攻击跟血量 第一步生成这四个属性,编程里就是定义四个变量:
随便叫什么都可以,a 或者 b ,c,d;为了方便区分我们可以写a1,a2,b1,b2
数值怎么取呢,利用刚才的随机模块的功能,不要问为什么,直接记住写这个函数就可以,
这就像我们生活中的工具,你要拧螺丝,就会想到用螺丝刀一样~慢慢熟悉!
②开始决斗 怎么决斗,血量减去敌人的攻击力,每一轮都是一人打一下 一方血量小于0他就死啦~!我们只要记住公式:
最新生命 = 生命 - 敌人攻击 (不断给生命这个变量赋值)
因为只打一下可能会打不死
所以上面这句话会重复出现!
怎 么 办?
重复出现相同的代码:用 循环!!!
不知道什么循环次数: 用 while
循环结束的条件:有一个人的生命小于0,游戏结束!
为了让游戏显示结果,需要用if else条件判断,根据不 同情况,显示不同内容。
这是一场游戏的代码
如果我们要进行三场游戏,把上面的结构循环三次就好啦!
利用for in range(3)循环三次。
添加三局两胜的计数功能:
在每次游戏内容判断结果的时候设置一个变量,赢了加1
最后比较大小就可以啦
第8关 编程思维:如何解决问题 1、瓶颈1:知识学完就忘 【案例笔记法 】
1.1、用法查询笔记
【用法查询笔记】就是记录知识点的基础用法,它是你的学习记录,能供你快速查阅,加深对知识的印象。其中代码含义往往用【#注释……】写在代码后面,实际运行效果往往用【# 》》注释……】写在代码下方。
1 2 3 4 5 6 7 8 9 10 11 ''' 知识:算术运算符 ''' print (2 +1 ) print (1 -2 ) print (1 *2 ) print (1 /2 )
1.2、深度理解笔记 【深度理解笔记】重在“理解”,所以笔记内容主要是记录对知识的理解。
理解:循环
1.3、知识管理
你会发现【深度理解笔记】和【用法查询笔记】本质上就是一个“字典嵌套列表”,其中【深度理解笔记】是键,【用法查询笔记】是值。
2、瓶颈2:缺乏解题能力 如何解题 2.1、分析问题,明确结果
假设我们的目标是在终端打印出这种格式的九九乘法表:
2.2、思考需要的知识,或搜索新知识
首先很明显,要打印信息就必须用到最基本的print()函数。
2.3、思考切入点
我们再来观察九九乘法表,我们会发现一个规律:每一行的等式里,第一位数会递增,第二位数则会保持不变,并且在第几行就会有多少个等式。
2.4、尝试解决问题的一部分 当循环次数是确定的时候,我们优先使用for循环。
1 2 3 1 X 2 = 2 2 X 2 = 4 1 X 3 = 3 2 X 3 = 6 3 X 3 = 9
1 2 3 4 5 6 7 8 9 10 11 12 13 for i in range (1 ,3 ): print ('%d X %d = %d' % (i,2 ,i*2 ),end = ' ' ) print ('' ) for i in range (1 ,4 ): print ('%d X %d = %d' % (i,3 ,i*3 ),end = ' ' ) print ('' ) for i in range (1 , 3 ): print (f'{i} X2={i*2 } ' , end=" " ) print ()for j in range (1 , 4 ): print (f'{j} X3={j * 3 } ' , end=" " )
循环嵌套
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 for i in range (1 ,10 ): for j in range (1 ,i+1 ): print ( '%d X %d = %d' % (j,i,i*j),end = ' ' ) print (' ' ) for i in range (1 ,10 ): for j in range (1 ,10 ): print ('%d X %d = %d' % (j,i,i*j),end = ' ' ) if i==j: print ('' ) break i = 1 while i <= 9 : j = 1 while j <= i: print ('%d X %d = %d' % (j,i,i*j),end = ' ' ) j += 1 print ('' ) i += 1
2.5、重复1-4步 升级版
1 2 3 4 for i in range (1 , 10 ): for j in range (1 , i+1 ): print (f'{i} X{j} ={i * j} ' , end=" " ) print ()
print函数的换行原理
其实print函数后面都会默认有一个end=‘\n’,也就是转义字符换行的意思,如果我们不希望print函数换行那么手动注明,end=‘’ 这样print函数就不会换行~
列表排序
合并列表,跟列表排序
这个是extend排序函数的应用 1 2 3 4 a = [1 ,2 ,3 ,4 ] b = [10 ,11 ,12 ,13 ] a.extend(b) print (a)
这个是sort排序函数的应用 1 2 3 b = [10 ,11 ,12 ,13 ,22 ,2 ] b.sort() print (b)
第9关 函数 1、函数是什么
函数(Function)能实现的功能从简单到复杂,各式各样,但其本质是相通的:“喂”给函数一些数据,它就能内部消化,给你“吐”出你想要的东西。组织好的、可以重复使用的、用来实现单一功能 的代码。
2、定义和调用函数
第一步,我们需要去定义一个函数,想象这个函数的名字、功能是什么。
2.1、定义函数 1 2 3 def 函数名 (参数1 , 参数2 ……参数n ): 函数体 return 语句
1 2 3 4 5 6 7 def greet (name ): print (name+'早上好' ) return
第1行:def的意思是定义(define),greet是【函数名】(自己取的),再搭配一个括号和冒号,括号里面的name是参数(参数名也是自己取)。
带参数函数
1 2 3 4 5 6 7 8 9 10 11 12 def pika1 (): print ('我最喜爱的神奇宝贝是皮卡丘' ) def pika2 (name ): print ('我最喜爱的神奇宝贝是' +name) def pika3 (name,person ): print ('我最喜爱的神奇宝贝是' +name) print ('我最喜爱的驯兽师是' +person)
第一个函数总是输出固定的一句话,所以不需要带参数。
2.2、调用函数
那怎么调用函数呢?很简单,喊出它的名字即可。在Python里,就是输入函数名和参数对应的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def pika1 (): print ('我最喜爱的神奇宝贝是皮卡丘' ) pika1() def pika2 (name ): print ('我最喜爱的神奇宝贝是' +name) pika2('皮卡丘' ) pika2('喷火龙' ) def pika3 (name,person ): print ('我最喜爱的神奇宝贝是' +name) print ('我最喜爱的驯兽师是' +person) pika3('卡比兽' ,'小智' )
圣诞树
1 2 3 4 5 6 def tree (Height ): print ('Merry Christmas!' ) for i in range (Height): print ((Height-i)*2 *' ' +'o' + i*'~x~o' ) print (((Height-i)*2 -1 )*' ' +(i*2 +1 )*'/' +'|' +(i*2 +1 )*'\\' ) tree(8 )
3、函数重要概念
设置与传递参数是函数的重点。
参数类型
主要的参数类型有:位置参数、默认参数、不定长参数。
1 2 3 4 5 def menu (appetizer,course ): print ('一份开胃菜:' +appetizer) print ('一份主食:' +course) menu('话梅花生' ,'牛肉拉面' )
这里的’话梅花生’和’牛肉拉面’是对应参数appetizer和course的位置顺序传递的,所以被叫作【位置参数】 ,这也是最常见的参数类型。
位置参数
1 2 3 4 5 6 7 8 9 10 def menu (appetizer,course ): print ('一份开胃菜:' +appetizer) print ('一份主食:' +course+'\n' ) menu('牛肉拉面' ,'话梅花生' ) menu('话梅花生' ,'牛肉拉面' ) menu(course='牛肉拉面' ,appetizer='话梅花生' )
默认参数
注意:默认参数必须放在位置参数之后。
1 2 3 4 5 6 7 def menu (appetizer,course,dessert='绿豆沙' ): print ('一份开胃菜:' +appetizer) print ('一份主食:' +course) print ('一份甜品:' +dessert) menu('话梅花生' ,'牛肉拉面' )
默认参数可以修改
1 2 3 4 5 6 7 8 9 def menu (appetizer,course,dessert='绿豆沙' ): print ('一份开胃菜:' +appetizer) print ('一份主食:' +course) print ('一份甜品:' +dessert) menu('话梅花生' ,'牛肉拉面' ) menu('话梅花生' ,'牛肉拉面' ,'银耳羹' )
不定长参数
是一个星号*加上参数名。
输出的值为元组。
1 2 3 4 5 def menu (*barbeque ): print (barbeque) menu('烤鸡翅' ,'烤茄子' ,'烤玉米' )
元组传参
1 2 3 4 5 order=('烤鸡翅' ,'烤茄子' ,'烤玉米' ) def menu (*barbeque ): print (barbeque) menu(*order)
默认参数也需要放在不定长参数的后面。
1 2 3 4 5 6 7 8 def menu (appetizer,course,*barbeque,dessert='绿豆沙' ): print ('一份开胃菜:' +appetizer) print ('一份主菜:' +course) print ('一份甜品:' +dessert) for i in barbeque: print ('一份烤串:' +i) menu('话梅花生' ,'牛肉拉面' ,'烤鸡翅' ,'烤茄子' ,'烤玉米' )
3.1、return语句
return是返回值,当你输入参数给函数,函数就会返回一个值给你。
函数可以互相嵌套。
1 2 3 4 5 6 7 8 9 def niduoda (age ): if age < 12 : return '哈,是祖国的花朵啊' elif age < 25 : return '哇,是小鲜肉呢' else : return '嗯,人生才刚刚开始' print (niduoda(30 ))
3.1.1、如果不是立即要对函数返回值做操作,那么可以使用return语句保留返回值。 一、分别定义两个函数,参数为人名,能够返回字符串’XXX的脸蛋’和’XXX的身材’;
二、将上述两个函数的返回值拼接在一起之后,再打印出来。
1 2 3 4 5 6 7 8 9 10 11 12 13 def face (name ): return name + '的脸蛋' def body (name ): return name + '的身材' face('李若彤' ) body('林志玲' ) print ('我的梦中情人:' +face('李若彤' ) +' + ' + body('林志玲' ))
函数可以互相嵌套,所以第7、8行调用face()和body()函数的两行代码可以省略,因为第12行的print()函数中其实已经有调用这两个函数了。
1 2 3 4 5 def face (name ): return name + '的脸蛋' def body (name ): return name + '的身材' print ('我的梦中情人:' +face('李若彤' ) +' + ' + body('林志玲' ))
但是这样的代码还有个问题,当我想多次调用函数的时候,就需要先复制print那行代码,再分别修改两个函数里的参数。这样的操作既不简洁,也不优雅。
1 2 3 4 5 6 7 def face (name ): return name + '的脸蛋' def body (name ): return name + '的身材' print ('我的梦中情人:' +face('李若彤' ) +' + ' + body('林志玲' ))print ('我的梦中情人:' +face('新垣结衣' ) +' + ' + body('长泽雅美' ))
所以更常见的做法是:再定义一个主函数main(),参数调用前两个函数的返回值。
3.1.2、需要多次调用函数时,可以再定义一个主函数main(),调用非主函数的返回值。 1 2 3 4 5 6 7 8 9 def face (name ): return name + '的脸蛋' def body (name ): return name + '的身材' def main (dream_face,dream_body ): return '我的梦中情人:' + face(dream_face) + ' + ' + body(dream_body) print (main('李若彤' ,'林志玲' ))print (main('新垣结衣' ,'长泽雅美' ))
main()函数内部分别调用了face()和body()函数,参数dream_face和dream_body传递给了face()和body()函数的参数name,得到返回值,并打印。
3.1.3、python的函数返回值可以是多个,多个返回值的数据类型是元组(tuple) 一次返回多个值
1 2 3 4 5 6 7 8 def lover (name1,name2 ): face = name1 + '的脸蛋' body = name2 + '的身材' return face,body a=lover('李若彤' ,'林志玲' ) print ('我的梦中情人:' +a[0 ]+' + ' +a[1 ])
3.1.4、没有return语句的函数会默认返回None值。 1 2 3 4 5 6 7 8 9 10 def fun (): a ='I am coding' print (fun())def fun (): a='I am coding' return a print (fun())
3.1.5、一旦函数内部遇到return语句,就会停止执行并返回结果。 1 2 3 4 5 def fun (): return 'I am coding.' return 'I am not coding.' print (fun())
题目是这样的:99的平方和8888赋值给参数,并将较大值打印出来。
1 2 3 4 5 6 7 8 9 def big_num (x,y ): if x>y: return x elif x==y: return '一样大' else : return y print (big_num(99 **2 ,8888 ))
3.2、变量作用域
第一点:在一个函数内定义的变量仅能在函数内部使用(局部作用域),它们被称作【局部变量】。
1 2 3 4 5 6 7 8 9 10 x=99 def num (): x=88 print (x) num() print (x)
你可以将定义的函数想象成一个私人房间,所以里面存数据的容器(变量)是私有的,只能在个人的房间里使用;而在函数外存数据的变量是公用的,没有使用限制。
全局作用域中的代码中也不能使用任何局部变量。
1 2 3 4 5 6 7 8 quantity = 108 def egg (): print (quantity) egg()
当变量处于被定义的函数内时,就是局部变量,只能在这个函数内被访问;当变量处于被定义的函数外时,就是全局变量,可以在程序中的任何位置被访问。
使用局部变量
global语句
1 2 3 4 5 6 7 def egg (): global quantity quantity = 108 egg() print (quantity)
报错
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def egg (): quantity = 108 egg() print (quantity) quantity = 108 def egg (): print (quantity) egg() def egg (): global quantity quantity = 108 egg() print (quantity)
函数的两个特性:
定义好之后不调用,那么函数的内部语句不会执行,有时候同学经常问我为什么我的代码写好了终端没反应,看一下是不是自己的函数只定义了,却没调用
其次多个函数配合时候还需要注意变量的作用域问题
函数外部定义的变量,如果函数内部对其修改,我们需要global声明。因为电脑需要知道你修改的变量指的是哪个变量,所以就需要进行声明,告诉电脑你修改的就是外面定义的那个
第10关 项目实操:PK小游戏(2) 1、明确项目目标 实现“田忌赛马”这个功能,即玩家可自行选择角色出场顺序,与电脑进行3V3的战斗。
项目
项目1
项目2
PK规模
1V1
3V3
PK视觉
角色名称简单,一成不变
据俄色色拥有姓名,且有变化(即随机生成)
PK策略
纯靠运气
可排序,有一定策略性
2、分析过程,拆解项目 项目1拆分-功能叠加
版本1.0:规定双方角色属性,战斗时人为计算扣血量,并打印出战斗过程;
项目2拆分-功能叠加
版本1.0:将项目1的部分代码。调整后用函数封装并调用。
3、逐步执行,代码实现 版本1.0:封装函数,自定属性 角色属性
1 2 3 4 5 6 7 def show_role (player_life,player_attack,enemy_life,enemy_attack ): print ('【玩家】\n血量:%s\n攻击:%s' %(player_life,player_attack)) print ('------------------------' ) print ('【敌人】\n血量:%s\n攻击:%s' %(enemy_life,enemy_attack)) print ('-----------------------' ) show_role(100 ,35 ,105 ,33 )
PK函数
1 2 3 4 5 6 7 8 9 import time def pk_role (player_life,player_attack,enemy_life,enemy_attack ): while player_life > 0 and enemy_life > 0 : player_life = player_life - enemy_attack enemy_life = enemy_life - player_attack time.sleep(1 ) print ('你发起了攻击,【敌人】剩余血量%s' %(enemy_life)) print ('敌人向你发起了攻击,【玩家】剩余血量%s' %(player_life)) print ('-----------------------' )
打印战果
1 2 3 4 5 6 7 8 9 def show_result (player_life,enemy_life ): if player_life > 0 and enemy_life <= 0 : print ('敌人死翘翘了,这局你赢了' ) elif player_life <= 0 and enemy_life > 0 : print ('悲催,这局敌人把你干掉了!' ) else : print ('哎呀,这局你和敌人同归于尽了!' ) print ('-----------------------' )
主函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import timedef show_role (player_life,player_attack,enemy_life,enemy_attack ): print ('【玩家】\n血量:%s\n攻击:%s' %(player_life,player_attack)) print ('------------------------' ) time.sleep(1 ) print ('【敌人】\n血量:%s\n攻击:%s' %(enemy_life,enemy_attack)) print ('-----------------------' ) def pk_role (player_life,player_attack,enemy_life,enemy_attack ): while player_life > 0 and enemy_life > 0 : player_life = player_life - enemy_attack enemy_life = enemy_life - player_attack time.sleep(1 ) print ('你发起了攻击,【敌人】剩余血量' +str (enemy_life)) print ('敌人向你发起了攻击,【玩家】剩余血量' +str (player_life)) print ('-----------------------' ) show_result(player_life,enemy_life) def show_result (player_life,enemy_life ): if player_life > 0 and enemy_life <= 0 : print ('敌人死翘翘了,这局你赢了' ) elif player_life <= 0 and enemy_life > 0 : print ('悲催,这局敌人把你干掉了!' ) else : print ('哎呀,这局你和敌人同归于尽了!' ) print ('-----------------------' ) def main (player_life,player_attack,enemy_life,enemy_attack ): show_role(player_life,player_attack,enemy_life,enemy_attack) pk_role(player_life,player_attack,enemy_life,enemy_attack) main(100 ,35 ,105 ,33 )
版本1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import timedef show_role (player_life,player_attack,enemy_life,enemy_attack ): print ('【玩家】\n血量:%s\n攻击:%s' %(player_life,player_attack)) print ('------------------------' ) time.sleep(1 ) print ('【敌人】\n血量:%s\n攻击:%s' %(enemy_life,enemy_attack)) print ('-----------------------' ) def pk_role (player_life,player_attack,enemy_life,enemy_attack ): while player_life > 0 and enemy_life > 0 : player_life = player_life - enemy_attack enemy_life = enemy_life - player_attack time.sleep(1 ) print ('你发起了攻击,【敌人】剩余血量' +str (enemy_life)) print ('敌人向你发起了攻击,【玩家】剩余血量' +str (player_life)) print ('-----------------------' ) show_result(player_life,enemy_life) def show_result (player_life,enemy_life ): if player_life > 0 and enemy_life <= 0 : print ('敌人死翘翘了,这局你赢了' ) elif player_life <= 0 and enemy_life > 0 : print ('悲催,这局敌人把你干掉了!' ) else : print ('哎呀,这局你和敌人同归于尽了!' ) print ('-----------------------' ) def main (player_life,player_attack,enemy_life,enemy_attack ): show_role(player_life,player_attack,enemy_life,enemy_attack) pk_role(player_life,player_attack,enemy_life,enemy_attack) main(100 ,35 ,105 ,33 ) main(120 ,36 ,100 ,45 ) main(100 ,35 ,100 ,35 )
版本2.0:随机角色,随机属性 随机选取语法
1 2 3 4 import random random.sample(seq, n)
随机生成角色
1 2 3 4 5 import randomplayer_list = ['【狂血战士】' ,'【森林箭手】' ,'【光明骑士】' ,'【独行剑客】' ,'【格斗大师】' ,'【枪弹专家】' ] players = random.sample (player_list,3 ) print (players)
为角色生成属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import randomplayer_list = ['【狂血战士】' ,'【森林箭手】' ,'【光明骑士】' ,'【独行剑客】' ,'【格斗大师】' ,'【枪弹专家】' ] players = random.sample(player_list,3 ) player_life = {} player_attack = {} life = random.randint(100 ,180 ) attack = random.randint(30 ,50 ) player_life[players[0 ]] = life player_attack[players[0 ]] = attack
单个角色
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import randomplayer_list = ['【狂血战士】' ,'【森林箭手】' ,'【光明骑士】' ,'【独行剑客】' ,'【格斗大师】' ,'【枪弹专家】' ] players = random.sample(player_list,3 ) player_life = {} player_attack = {} life = random.randint(100 ,180 ) attack = random.randint(30 ,50 ) player_life[players[0 ]] = life player_attack[players[0 ]] = attack print ('----------------- 角色信息 -----------------' )print ('你的人物:' )print ('%s 血量:%d 攻击:%d' %(players[0 ],player_life[players[0 ]],player_attack[players[0 ]])) print ('--------------------------------------------' )
三个角色
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import randomplayer_list = ['【狂血战士】' ,'【森林箭手】' ,'【光明骑士】' ,'【独行剑客】' ,'【格斗大师】' ,'【枪弹专家】' ] players = random.sample(player_list,3 ) player_life = {} player_attack = {} for i in range (3 ): life = random.randint(100 ,180 ) attack = random.randint(30 ,50 ) player_life[players[i]] = life player_attack[players[i]] = attack print ('----------------- 角色信息 -----------------' )print ('你的人物:' )for i in range (3 ): print ('%s 血量:%d 攻击:%d' %(players[i],player_life[players[i]],player_attack[players[i]])) print ('--------------------------------------------' )
我方信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import randomplayer_list = ['【狂血战士】' ,'【森林箭手】' ,'【光明骑士】' ,'【独行剑客】' ,'【格斗大师】' ,'【枪弹专家】' ] players = random.sample(player_list,3 ) player_life = {} player_attack = {} def show_role (): for i in range (3 ): life = random.randint(100 ,180 ) attack = random.randint(30 ,50 ) player_life[players[i]] = life player_attack[players[i]] = attack print ('----------------- 角色信息 -----------------' ) print ('你的人物:' ) for i in range (3 ): print ('%s 血量:%d 攻击:%d' %(players[i],player_life[players[i]],player_attack[players[i]])) print ('--------------------------------------------' ) show_role()
元组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import randomplayer = ['狂血战士' ] dict1 = {} def info (): a = random.randint(1 ,3 ) b = random.randint(4 ,6 ) return a,b data = info() print (data)dict1[player[0 ]] = data print (dict1) print (dict1[player[0 ]]) print (dict1[player[0 ]][0 ]) print (dict1[player[0 ]][1 ])
我方三个角色信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import randomplayer_list = ['【狂血战士】' ,'【森林箭手】' ,'【光明骑士】' ,'【独行剑客】' ,'【格斗大师】' ,'【枪弹专家】' ] players = random.sample(player_list,3 ) player_info = {} def born_role (): life = random.randint(100 ,180 ) attack = random.randint(30 ,50 ) return life,attack def show_role (): for i in range (3 ): player_info[players[i]] = born_role() print ('----------------- 角色信息 -----------------' ) print ('你的人物:' ) for i in range (3 ): print ('%s 血量:%d 攻击:%d' %(players[i],player_info[players[i]][0 ],player_info[players[i]][1 ])) print ('--------------------------------------------' ) show_role()
2.0版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import time,randomplayer_list = ['【狂血战士】' ,'【森林箭手】' ,'【光明骑士】' ,'【独行剑客】' ,'【格斗大师】' ,'【枪弹专家】' ] enemy_list = ['【暗黑战士】' ,'【黑暗弩手】' ,'【暗夜骑士】' ,'【嗜血刀客】' ,'【首席刺客】' ,'【陷阱之王】' ] players = random.sample(player_list,3 ) enemies = random.sample(enemy_list,3 ) player_info = {} enemy_info = {} def born_role (): life = random.randint(100 ,180 ) attack = random.randint(30 ,50 ) return life,attack def show_role (): for i in range (3 ): player_info[players[i]] = born_role() enemy_info[enemies[i]] = born_role() print ('----------------- 角色信息 -----------------' ) print ('你的人物:' ) for i in range (3 ): print ('%s 血量:%d 攻击:%d' %(players[i],player_info[players[i]][0 ],player_info[players[i]][1 ])) print ('--------------------------------------------' ) print ('电脑敌人:' ) for i in range (3 ): print ('%s 血量:%d 攻击:%d' %(enemies[i],enemy_info[enemies[i]][0 ],enemy_info[enemies[i]][1 ])) print ('--------------------------------------------' ) show_role()
版本3.0:询问玩家出场顺序
1.分别询问玩家每个角色的出场顺序,根据玩家的排序来战斗
开始3轮战斗,并输出单轮和最终结果。
选择顺序
1 2 3 4 5 6 7 list1 = ['A' ,'B' ,'C' ] dict1 = {} for i in range (3 ): order = int (input ('你要把' +list1[i]+'放在第几位?(请输入数字1,2,3)' )) dict1[order] = list1[i] print (dict1)
取值
1 2 3 4 5 6 7 8 9 10 11 12 dict1 = {3 :'A' ,2 :'B' ,1 :'C' } print (dict1[1 ])print (dict1[2 ])print (dict1[3 ])list1 = [] list1.append(dict1[1 ]) list1.append(dict1[2 ]) list1.append(dict1[3 ]) print (list1)
优化
1 2 3 4 5 6 dict1 = {3 :'A' ,2 :'B' ,1 :'C' } list1 = [] for i in range (1 ,4 ): list1.append(dict1[i])
排列顺序代码
1 2 3 4 5 6 7 8 9 10 11 12 list1 = ['A' ,'B' ,'C' ] dict1 = {} for i in range (3 ): order = int (input ('你要把' +list1[i]+'放在第几位?(请输入数字1,2,3)' )) dict1[order] = list1[i] print (dict1) list1 = [] for i in range (1 ,4 ): list1.append(dict1[i]) print (list1)
出场顺序
1 2 3 4 5 6 7 8 9 10 11 12 13 players = ['【狂血战士】' ,'【森林箭手】' ,'【光明骑士】' ] order_dict = {} for i in range (3 ): order = int (input ('你想将 %s 放在第几个上场?(输入数字1~3)' % players[i])) order_dict[order] = players[i] players = [] for i in range (1 ,4 ): players.append(order_dict[i]) print ('\n我方角色的出场顺序是:%s、%s、%s' % (players[0 ],players[1 ],players[2 ]))
封装排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 players = ['【狂血战士】' ,'【森林箭手】' ,'【光明骑士】' ] order_dict = {} for i in range (3 ): order = int (input ('你想将 %s 放在第几个上场?(输入数字1~3)' % players[i])) order_dict[order] = players[i] players = [] for i in range (1 ,4 ): players.append(order_dict[i]) print ('\n我方角色的出场顺序是:%s、%s、%s' % (players[0 ],players[1 ],players[2 ]))players = ['【狂血战士】' ,'【森林箭手】' ,'【光明骑士】' ] def order_role (): global players order_dict = {} for i in range (3 ): order = int (input ('你想将 %s 放在第几个上场?(输入数字1~3)' %(players[i]))) order_dict[order] = players[i] players = [] for i in range (1 ,4 ): players.append(order_dict[i]) print ('\n我方角色的出场顺序是:%s、%s、%s' %(players[0 ],players[1 ],players[2 ]))
合并代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import randomplayer_list = ['【狂血战士】' ,'【森林箭手】' ,'【光明骑士】' ,'【独行剑客】' ,'【格斗大师】' ,'【枪弹专家】' ] enemy_list = ['【暗黑战士】' ,'【黑暗弩手】' ,'【暗夜骑士】' ,'【嗜血刀客】' ,'【首席刺客】' ,'【陷阱之王】' ] players = random.sample(player_list,3 ) enemies = random.sample(enemy_list,3 ) player_info = {} enemy_info = {} def born_role (): life = random.randint(100 ,180 ) attack = random.randint(30 ,50 ) return life,attack def show_role (): for i in range (3 ): player_info[players[i]] = born_role() enemy_info[enemies[i]] = born_role() print ('----------------- 角色信息 -----------------' ) print ('你的人物:' ) for i in range (3 ): print ('%s 血量:%d 攻击:%d' %(players[i],player_info[players[i]][0 ],player_info[players[i]][1 ])) print ('--------------------------------------------' ) print ('电脑敌人:' ) for i in range (3 ): print ('%s 血量:%d 攻击:%d' %(enemies[i],enemy_info[enemies[i]][0 ],enemy_info[enemies[i]][1 ])) print ('--------------------------------------------' ) input ('请按回车键继续。\n' ) def order_role (): global players order_dict = {} for i in range (3 ): order = int (input ('你想将 %s 放在第几个上场?(输入数字1~3)' %(players[i]))) order_dict[order] = players[i] players = [] for i in range (1 ,4 ): players.append(order_dict[i]) print ('\n我方角色的出场顺序是:%s、%s、%s' %(players[0 ],players[1 ],players[2 ])) print ('敌方角色的出场顺序是:%s、%s、%s' %(enemies[0 ],enemies[1 ],enemies[2 ])) def main (): show_role() order_role() main()
版本4.0:3V3战斗,输出战果
我们只要再加上“角色PK”的过程,同时展示战果,这个游戏便完成了。
这个过程,其实和项目1的最终代码很类似。互相PK,三局两胜。我们可以将其拆解为3部分:角色PK、打印单局战果和打印最终结果。
三局制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 import timeplayers = ['【狂血战士】' ,'【森林箭手】' ,'【光明骑士】' ] enemies = ['【暗黑战士】' ,'【黑暗弩手】' ,'【暗夜骑士】' ] player_info = {'【狂血战士】' :(105 ,35 ),'【森林箭手】' :(105 ,35 ),'【光明骑士】' :(105 ,35 )} enemy_info = {'【暗黑战士】' :(105 ,35 ),'【黑暗弩手】' :(105 ,35 ),'【暗夜骑士】' :(105 ,35 )} input ('按回车开始简化版游戏:' )def pk_role (): round = 1 score = 0 for i in range (3 ): player_name = players[i] enemy_name = enemies[i] player_life = player_info[players[i]][0 ] player_attack = player_info[players[i]][1 ] enemy_life = enemy_info[enemies[i]][0 ] enemy_attack = enemy_info[enemies[i]][1 ] print ('\n----------------- 【第%d局】 -----------------' % round ) print ('玩家角色:%s vs 敌方角色:%s ' % (player_name,enemy_name)) print ('%s 血量:%d 攻击:%d' % (player_name,player_life,player_attack)) print ('%s 血量:%d 攻击:%d' % (enemy_name,enemy_life,enemy_attack)) print ('--------------------------------------------' ) input ('请按回车键继续。\n' ) while player_life > 0 and enemy_life > 0 : enemy_life = enemy_life - player_attack player_life = player_life - enemy_attack print ('%s发起了攻击,%s剩余血量%d' % (player_name,enemy_name,enemy_life)) print ('%s发起了攻击,%s剩余血量%d' % (enemy_name,player_name,player_life)) print ('--------------------------------------------' ) time.sleep(1 ) else : if player_life > 0 and enemy_life <= 0 : print ('\n敌人死翘翘了,你赢了!' ) score += 1 elif player_life <= 0 and enemy_life > 0 : print ('\n悲催,敌人把你干掉了!' ) score += -1 else : print ('\n哎呀,你和敌人同归于尽了!' ) score += 0 round += 1 input ('\n点击回车,查看比赛的最终结果\n' ) if score > 0 : print ('【最终结果:你赢了!】\n' ) elif score < 0 : print ('【最终结果:你输了!】\n' ) else : print ('【最终结果:平局!】\n' ) pk_role()
函数优化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 import timeplayers = ['【狂血战士】' ,'【森林箭手】' ,'【光明骑士】' ] enemies = ['【暗黑战士】' ,'【黑暗弩手】' ,'【暗夜骑士】' ] player_info = {'【狂血战士】' :(105 ,35 ),'【森林箭手】' :(105 ,35 ),'【光明骑士】' :(105 ,35 )} enemy_info = {'【暗黑战士】' :(105 ,35 ),'【黑暗弩手】' :(105 ,35 ),'【暗夜骑士】' :(105 ,35 )} input ('按回车开始简化版游戏:' )def pk_role (): round = 1 score = 0 for i in range (3 ): player_name = players[i] enemy_name = enemies[i] player_life = player_info[players[i]][0 ] player_attack = player_info[players[i]][1 ] enemy_life = enemy_info[enemies[i]][0 ] enemy_attack = enemy_info[enemies[i]][1 ] print ('\n----------------- 【第%d局】 -----------------' % round ) print ('玩家角色:%s vs 敌方角色:%s ' %(player_name,enemy_name)) print ('%s 血量:%d 攻击:%d' %(player_name,player_life,player_attack)) print ('%s 血量:%d 攻击:%d' %(enemy_name,enemy_life,enemy_attack)) print ('--------------------------------------------' ) input ('请按回车键继续。\n' ) while player_life > 0 and enemy_life > 0 : enemy_life = enemy_life - player_attack player_life = player_life - enemy_attack print ('%s发起了攻击,%s剩余血量%d' %(player_name,enemy_name,enemy_life)) print ('%s发起了攻击,%s剩余血量%d' %(enemy_name,player_name,player_life)) print ('--------------------------------------------' ) time.sleep(1 ) else : print (show_result(player_life,enemy_life)[1 ]) score += int (show_result(player_life,enemy_life)[0 ]) round += 1 input ('\n点击回车,查看比赛的最终结果\n' ) if score > 0 : print ('【最终结果:你赢了!】\n' ) elif score < 0 : print ('【最终结果:你输了!】\n' ) else : print ('【最终结果:平局!】\n' ) def show_result (player_life,enemy_life ): if player_life > 0 and enemy_life <= 0 : result = '\n敌人死翘翘了,你赢了!' return 1 ,result elif player_life <= 0 and enemy_life > 0 : result = '\n悲催,敌人把你干掉了!' return -1 ,result else : result = '\n哎呀,你和敌人同归于尽了!' return 0 ,result pk_role()
完整版
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 import time,randomplayer_list = ['【狂血战士】' ,'【森林箭手】' ,'【光明骑士】' ,'【独行剑客】' ,'【格斗大师】' ,'【枪弹专家】' ] enemy_list = ['【暗黑战士】' ,'【黑暗弩手】' ,'【暗夜骑士】' ,'【嗜血刀客】' ,'【首席刺客】' ,'【陷阱之王】' ] players = random.sample(player_list,3 ) enemies = random.sample(enemy_list,3 ) player_info = {} enemy_info = {} def born_role (): life = random.randint(100 ,180 ) attack = random.randint(30 ,50 ) return life,attack def show_role (): for i in range (3 ): player_info[players[i]] = born_role() enemy_info[enemies[i]] = born_role() print ('----------------- 角色信息 -----------------' ) print ('你的人物:' ) for i in range (3 ): print ('%s 血量:%d 攻击:%d' %(players[i],player_info[players[i]][0 ],player_info[players[i]][1 ])) print ('--------------------------------------------' ) print ('电脑敌人:' ) for i in range (3 ): print ('%s 血量:%d 攻击:%d' %(enemies[i],enemy_info[enemies[i]][0 ],enemy_info[enemies[i]][1 ])) print ('--------------------------------------------' ) input ('请按回车键继续。\n' ) def order_role (): global players order_dict = {} for i in range (3 ): order = int (input ('你想将 %s 放在第几个上场?(输入数字1~3)' % players[i])) order_dict[order] = players[i] players = [] for i in range (1 ,4 ): players.append(order_dict[i]) print ('\n我方角色的出场顺序是:%s、%s、%s' %(players[0 ],players[1 ],players[2 ])) print ('敌方角色的出场顺序是:%s、%s、%s' %(enemies[0 ],enemies[1 ],enemies[2 ])) def pk_role (): round = 1 score = 0 for i in range (3 ): player_name = players[i] enemy_name = enemies[i] player_life = player_info[players[i]][0 ] player_attack = player_info[players[i]][1 ] enemy_life = enemy_info[enemies[i]][0 ] enemy_attack = enemy_info[enemies[i]][1 ] print ('\n----------------- 【第%d局】 -----------------' % round ) print ('玩家角色:%s vs 敌方角色:%s ' %(player_name,enemy_name)) print ('%s 血量:%d 攻击:%d' %(player_name,player_life,player_attack)) print ('%s 血量:%d 攻击:%d' %(enemy_name,enemy_life,enemy_attack)) print ('--------------------------------------------' ) input ('请按回车键继续。\n' ) while player_life > 0 and enemy_life > 0 : enemy_life = enemy_life - player_attack player_life = player_life - enemy_attack print ('%s发起了攻击,%s剩余血量%d' % (player_name,enemy_name,enemy_life)) print ('%s发起了攻击,%s剩余血量%d' % (enemy_name,player_name,player_life)) print ('--------------------------------------------' ) time.sleep(1 ) else : print (show_result(player_life,enemy_life)[1 ]) score += int (show_result(player_life,enemy_life)[0 ]) round += 1 input ('\n点击回车,查看比赛的最终结果\n' ) if score > 0 : print ('【最终结果:你赢了!】\n' ) elif score < 0 : print ('【最终结果:你输了!】\n' ) else : print ('【最终结果:平局!】\n' ) def show_result (player_life,enemy_life ): if player_life > 0 and enemy_life <= 0 : result = '\n敌人死翘翘了,你赢了!' return 1 ,result elif player_life <= 0 and enemy_life > 0 : result = '\n悲催,敌人把你干掉了!' return -1 ,result else : result = '\n哎呀,你和敌人同归于尽了!' return 0 ,result def main (): show_role() order_role() pk_role() main()
第11关 编程思维:如何debug bug 1:粗心
1、漏了末尾的冒号,如if语句、循环语句、定义函数
bug 2:知识不熟练 bug 3:思路不清 解决思路不清的两个工具
1、print()函数
解决思路不清bug的三步法
1、用#把感觉会出问题的代码注释掉
bug 4:被动掉坑 异常处理的机制 try…except…
1 2 3 4 5 6 7 8 9 10 try : ... ... except ***: ... ...
报错类型是“ValueError”
1 2 3 4 5 6 7 8 try : age = int (input ('你今年几岁了?' )) if age < 18 : print ('不可以喝酒噢' ) except ValueError: print ('要输入整数哦' )
python标准异常
异常名称
描述
BaseException
所有异常的基类
SystemExit
解释器请求退出
KeyboardInterrupt
用户中断执行(通常是输入^C)
Exception
常规错误的基类
StopIteration
迭代器没有更多的值
GeneratorExit
生成器(generator)发生异常来通知退出
StandardError
所有的内建标准异常的基类
ArithmeticError
所有数值计算错误的基类
FloatingPointError
浮点计算错误
OverflowError
数值运算超出最大限制
ZeroDivisionError
除(或取模)零 (所有数据类型)
AssertionError
断言语句失败
AttributeError
对象没有这个属性
EOFError
没有内建输入,到达EOF 标记
EnvironmentError
操作系统错误的基类
IOError
输入/输出操作失败
OSError
操作系统错误
WindowsError
系统调用失败
ImportError
导入模块/对象失败
LookupError
无效数据查询的基类
IndexError
序列中没有此索引(index)
KeyError
映射中没有这个键
MemoryError
内存溢出错误(对于Python 解释器不是致命的)
NameError
未声明/初始化对象 (没有属性)
UnboundLocalError
访问未初始化的本地变量
ReferenceError
弱引用(Weak reference)试图访问已经垃圾回收了的对象
RuntimeError
一般的运行时错误
NotImplementedError
尚未实现的方法
SyntaxError
Python 语法错误
IndentationError
缩进错误
TabError
Tab 和空格混用
SystemError
一般的解释器系统错误
TypeError
对类型无效的操作
ValueError
传入无效的参数
UnicodeError
Unicode 相关的错误
UnicodeDecodeError
Unicode 解码时的错误
UnicodeEncodeError
Unicode 编码时错误
UnicodeTranslateError
Unicode 转换时错误
Warning
警告的基类
DeprecationWarning
关于被弃用的特征的警告
FutureWarning
关于构造将来语义会有改变的警告
OverflowWarning
旧的关于自动提升为长整型(long)的警告
PendingDeprecationWarning
关于特性将会被废弃的警告
RuntimeWarning
可疑的运行时行为(runtime behavior)的警告
SyntaxWarning
可疑的语法的警告
UserWarning
用户代码生成的警告
第12关 类与对象1 1、类与对象 事情要从“类”开始讲起
现实世界
编程世界
类
人类;电脑类
整数类、字符串类等
实例
你、我;这台电脑、那台电脑
1、2;’第一个例子’、’第二个例子’
万事万物,皆为对象
Python中的对象等于类和实例的集合:即类可以看作是对象,实例也可以看作是对象,比如列表list是个类对象,[1,2]是个实例对象,它们都是对象。
2、类的创建和调用 我们都是中国人
我们都属于中国人这个类,所以我们(作为实例)存在一些共同点。
现实
编程
例子
中国人这个类,属性有:黑眼睛、黄皮肤等,方法有:用筷子吃饭、讲汉语等
列表类的属性有:外层都有中括号等,方法有:del、append等
共同点
类的属性和方法,是这个类下的每个实例都有的。每个实例都可调用类中的属性和方法
类的属性和方法,是这个类下的每个实例都有的。每个实例都可调用类中的属性和方法
不同点
现实中类的属性和方法是客观存在的,编程中的类的属性和方法是人工创建的。
现实中类的属性和方法是客观存在的,编程中的类的属性和方法是人工创建的。
类的创建 电脑类
1 2 3 4 5 6 class Computer : screen = True def start (self ): print ('电脑正在开机中……' )
创建中国人类
1 2 3 4 5 6 7 8 class Chinese : eye = 'black' def eat (self ): print ('吃饭,选择用筷子。' )
类的调用 1 2 3 4 5 6 7 8 9 class Computer : screen = True def start (self ): print ('电脑正在开机中……' ) my_computer = Computer() print (my_computer.screen)my_computer.start()
调用:类的实例化,即在某个类下创建一个实例对象。
类的实例化
语法:实例名=类名()my_computer一被创建出来,就可以调用类中的属性和方法。
调用 调用的语法是实例名.属性和实例名.方法
1 2 3 4 5 6 7 8 9 class Computer : screen = True def start (self ): print ('电脑正在开机中……' ) my_computer = Computer() my_computer.start()
参数self的特殊之处:在定义时不能丢,在调用时要忽略。
1 2 3 4 5 6 7 8 9 class Chinese : eye = 'black' def eat (self ): print ('吃饭,选择用筷子。' ) wufeng = Chinese() print (wufeng.eye) wufeng.eat()
类的创建和调用
类的创建:class语句
类的实例化:实例名 = 类名()
类中创建的属性和方法可以被其所有的实例调用,而且,实例的数目在理论上是无限的。
3、创建类的两个关键点 特殊参数:self
self会接收实例化过程中传入的数据,当实例对象创建后,实例便会代替 self,在代码中运行。
如果想在类的内部调用类属性,而实例又还没创建之前,我们就需要有个变量先代替实例接收数据,这个变量就是参数self。
1 2 3 4 5 6 7 8 9 class Chinese : name = '吴枫' def say (self ): print (self.name + '是中国人' ) person = Chinese() person.say()
1 2 3 4 5 6 7 8 9 10 11 12 13 class Chinese : def greeting (self ): print ('很高兴遇见你' ) def say (self ): self.greeting() print ('我来自中国' ) person = Chinese() person.say()
第一点:只要在类中用def创建方法时,就必须把第一个参数 位置留给 self,并在调用方法时忽略它(不用给self传参)。
第二点:当在类的方法内部 想调用类属性或其他方法时,就要采用self.属性名或self.方法名的格式。
特殊方法:初始化方法
当每个实例对象创建时,该方法内的代码无须调用就会自动运行。
初始化方法
1 2 3 4 5 6 7 class Chinese : def __init__ (self ): print ('很高兴遇见你,我是初始化方法' ) person = Chinese()
传参初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Chinese : def __init__ (self, name, birth, region ): self.name = name self.birth = birth self.region = region def born (self ): print (self.name + '出生在' + self.birth) def live (self ): print (self.name + '居住在' + self.region) person = Chinese('吴枫' ,'广东' ,'深圳' ) person.born() person.live()
11
1 2 3 4 5 6 7 8 9 10 11 class Chinese : def __init__ (self, hometown ): self.hometown = hometown print ('你在哪里出生?' ) def born (self ): print ('我生在%s。' % self.hometown) wufeng = Chinese('广东' ) wufeng.born()
4、面向对象编程
面向过程编程:首先分析出解决问题所需要的步骤(即“第一步做什么,第二步做什么,第三步做什么”),然后用函数实现各个步骤,再依次调用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 import mathkey = 1 def myinput (): choice = input ('请选择计算类型:(1-工时计算,2-人力计算)' ) if choice == '1' : size = float (input ('请输入项目大小:(1代表标准大小,请输入小数)' )) number = int (input ('请输入人力数量:(请输入整数)' )) time = None return size,number,time if choice == '2' : size = float (input ('请输入项目大小:(1代表标准大小,请输入小数)' )) number = None time = float (input ('请输入工时数量:(请输入小数)' )) return size,number,time def estimated (my_input ): size = my_input[0 ] number = my_input[1 ] time = my_input[2 ] if (number == None ) and (time != None ): number = math.ceil(size * 80 / time) print ('项目大小为%.1f个标准项目,如果需要在%.1f个工时完成,则需要人力数量为:%d人' %(size,time,number)) elif (number != None ) and (time == None ): time = size * 80 / number print ('项目大小为%.1f个标准项目,使用%d个人力完成,则需要工时数量为:%.1f个' %(size,number,time)) def again (): global key a = input ('是否继续计算?继续请输入y,输入其他键将结束程序。' ) if a != 'y' : key = 0 def main (): print ('欢迎使用工作量计算小程序!' ) while key == 1 : my_input = myinput() estimated(my_input) again() print ('感谢使用工作量计算小程序!' ) main()
我们根据“采集信息——计算数据——继续采集信息”这个过程封装了三个函数,再依次调用,按规定顺序执行程序。
而面向对象编程,会将程序看作是一组对象的集合(还记得对象包括类对象和实例对象吧)。
用这种思维设计代码时,考虑的不是程序具体的执行过程(即先做什么后做什么),而是考虑先创建某个类,在类中设定好属性和方法,即是什么,和能做什么。
接着,再以类为模版创建一个实例对象,用这个实例去调用类中定义好的属性和方法即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import mathclass Project : def __init__ (self ): self.key = 1 def input (self ): choice = input ('请选择计算类型:(1-工时计算,2-人力计算)' ) if choice == '1' : self.size = float (input ('请输入项目大小:(1代表标准大小,请输入小数)' )) self.number = int (input ('请输入人力数量:(请输入整数)' )) self.time = None if choice == '2' : self.size = float (input ('请输入项目大小:(1代表标准大小,请输入小数)' )) self.number = None self.time = float (input ('请输入工时数量:(请输入小数)' )) def estimated (self ): if (self.number == None ) and (self.time != None ): self.number = math.ceil(self.size * 80 / self.time) print ('项目大小为%.1f个标准项目,如果需要在%.1f个工时完成,则需要人力数量为:%d人' %(self.size,self.time,self.number)) elif (self.number != None ) and (self.time == None ): self.time = self.size * 80 / self.number print ('项目大小为%.1f个标准项目,使用%d个人力完成,则需要工时数量为:%.1f个' %(self.size,self.number,self.time)) def again (self ): a = input ('是否继续计算?继续请输入y,输入其他键将结束程序。' ) if a != 'y' : self.key = 0 def main (self ): print ('欢迎使用工作量计算小程序!' ) while self.key == 1 : self.input () self.estimated() self.again() print ('感谢使用工作量计算小程序!' ) project1 = Project() project1.main()
面向对象编程:以对象为中心,将计算机程序看作一组对象的集合。
面向对象编程
面向过程编程
中心
以对象为中心
以过程为中心
知识点
类的创建和调用
函数的创建和调用
程序组成
一组对象的集合
一系列过程的集合
适用场景
较复杂,尤其是持续更新的代码
较简单,且功能较为稳定的代码
总结一下:和之前说过的函数类似,面向对象编程实际上也是一种对代码的封装。只不过,类能封装更多的东西,既能包含操作数据的方法,又能包含数据本身。所以,代码的可复用性也更高。
对象object (类和实例的集合)
第13关 类与对象2 1、类的继承和定制是什么? 1 2 3 4 5 6 7 8 9 10 11 12 13 class Chinese : eye = 'black' def __init__ (self,hometown ): self.hometown = hometown print ('程序持续更新中……' ) def born (self ): print ('我生在%s。' %(self.hometown)) wufeng = Chinese('广东' ) print (wufeng.eye) wufeng.born()
1.1、继承,从广东人说起
把他脑子里对“中国人”这个类的所有信息都复制了一份,然后放到了“广东人”这个类下面。
类的继承,让子类拥有了父类拥有的所有属性和方法。
1.2、定制,广东人又来了
广东人除了继承中国人的属性方法外,还可以创造【属于自己】的属性或方法,如籍贯开头是广东省(属性)、会说广东话(方法)。
类的定制,不仅可以让子类拥有新的功能,还能让它有权修改继承到的代码——在写这句话时,我仿佛看到子类化成了一个人,抬头瞟了一眼在他上方的父类,淡淡地说了一句话:以我为主,为我所用。
2、类的继承,要怎么写? 2.1、继承的基础语法
A子类名
继承 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Chinese : eye = 'black' def eat (self ): print ('吃饭,选择用筷子。' ) class Cantonese (Chinese ): pass yewen = Cantonese() print (yewen.eye) yewen.eat()
根类
很多类在创建时也不带括号,如class Chinese:。class Chinese:在运行时相当于class Chinese(object):。而object,是所有类的父类,我们将其称为根类(可理解为类的始祖)。isinstance(),可以用来判断某个实例是否属于某个类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Chinese : pass class Cantonese (Chinese ): pass gonger = Chinese() yewen = Cantonese() print ('\n验证1:子类创建的实例同时也属于父类' )print (isinstance (gonger,Chinese)) print (isinstance (yewen,Chinese)) print ('\n验证2:父类创建的实例不属于子类。' )print (isinstance (gonger,Cantonese))print ('\n验证3:类创建的实例都属于根类。' )print (isinstance (gonger,object )) print (isinstance (yewen,object ))
各级实例和各级类间的关系
1、子类创建的实例,同时属于父类
2.2、类的继承之多层继承
实例yewen可以调用父类Chinese和父类的父类Earthman中的属性。可得结论:子类创建的实例可调用所有层级父类的属性和方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Earthman : eye_number = 2 class Chinese (Earthman ): eye_color = 'black' class Cantonese (Chinese ): pass yewen = Cantonese() print (yewen.eye_number)print (yewen.eye_color)
2.3、类的继承之多重继承
一个类,可以同时继承多个类,语法为class A(B,C,D):。假设我们将“出生在江苏,定居在广东的人”设为一个类Yuesu,那么,它的创建语句则为class Yuesu(Yue,Su)。class Yuesu(Yue,Su)括号里Yue和Su的顺序是有讲究的。和子类更相关的父类会放在更左侧。我认为“出生在江苏,定居在广东的人”在穿着和饮食等方面会更接近广东人,所以将 Yue 放在 Su 的左侧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Su : born_city = 'Jiangsu' wearing = 'thick' def diet (self ): print ('我们爱吃甜。' ) class Yue : settle_city = 'Guangdong' wearing = 'thin' def diet (self ): print ('我们吃得清淡。' ) class Yuesu (Yue,Su): pass xiaoming = Yuesu() print (xiaoming.wearing)print (xiaoming.born_city)xiaoming.diet()
多层继承
多重继承
class B(A):
class A(B,C,D):
class C(B):
作用:类在纵向上的深度拓展
作用:类在横向上的宽度拓展
例子:中国人继承自地球人,广东人又继承自中国人。
例子:在广东定居的江苏人,同时继承了广东人和江苏人的一些特征。
特点:子类创建的实例,可调用所有层级的父类的属性和方法。
特点:就近原则:在子类调用属性和方法时,优先考虑靠近子类(即靠左)的父类。
重继承中,若某父类还有父类的话,会先继续往上找到顶。例如代码中的ins.name调用的是C2的父类C0 的值而非 C3。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class C0 : name = 'C0' class C2 (C0 ): num = 2 class C1 : num = 1 class C3 : name = 'C3' class C4 (C1,C2,C3): pass ins = C4() print (ins.name) print (ins.num)
3、类的定制,要怎么写? 3.1、定制,可以新增代码
我们可以在子类下新建属性或方法,让子类可以用上父类所没有的属性或方法。这种操作,属于定制中的一种:新增代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Chinese : eye = 'black' def eat (self ): print ('吃饭,选择用筷子。' ) class Cantonese (Chinese ): native_place = 'guangdong' def dialect (self ): print ('我们会讲广东话。' ) yewen = Cantonese() print (yewen.eye)print (yewen.native_place)yewen.eat() yewen.dialect()
3.2、定制,也可重写代码
重写代码,是在子类中,对父类代码的修改。
直接重写(不推荐) 1 2 3 4 5 6 7 8 9 10 11 12 13 class Chinese : def land_area (self,area ): print ('我们居住的地方,陆地面积是%d万平方公里左右。' % area) class Cantonese (Chinese ): def land_area (self,area ): print ('我们居住的地方,陆地面积是%d万平方公里左右。' % int (area*0.0188 )) gonger = Chinese() yewen = Cantonese() gonger.land_area(960 ) yewen.land_area(960 )
间接重写(推荐)
子类继承父类方法的操作是在def语句后接父类.方法(参数)land_area中的说法改变,子类也不用去动,因为子类直接继承了父类的方法。只不过,在继承的基础上,通过参数的调整完成了定制。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Chinese : def land_area (self,area ): print ('我们居住的地方,陆地面积是%d万平方公里左右。' % area) class Cantonese (Chinese ): def land_area (self, area, rate = 0.0188 ): Chinese.land_area(self, area * rate) gonger = Chinese() yewen = Cantonese() gonger.land_area(960 ) yewen.land_area(960 )
设置默认值
1 2 3 4 5 6 7 8 9 10 11 12 13 class Chinese : def land_area (self,area ): print ('我们居住的地方,陆地面积是%d万平方公里左右。' % area) class Cantonese (Chinese ): def land_area (self, area = 960 , rate = 0.0188 ): Chinese.land_area(self, area * rate) yewen = Cantonese() yewen.land_area()
雷猴!欢迎来到广东。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Chinese : def __init__ (self, greeting = '你好' , place = '中国' ): self.greeting = greeting self.place = place def greet (self ): print ('%s!欢迎来到%s。' % (self.greeting, self.place)) class Cantonese (Chinese ): def __init__ (self, greeting = '雷猴' , place = '广东' ): Chinese.__init__(self, greeting, place) yewen = Cantonese() yewen.greet()
第14关 项目实操:PK小游戏(3) 1、明确项目目标
1、查询书籍 :可以一键查询系统里所有书籍的基本信息和借阅状态2、添加书籍 :往系统添加书籍时,需要输入书籍的基本信息(书名、作家、推荐语)3、借阅书籍 :当书籍的借阅状态是“未借出”的时候,书籍才可出借,接触后状态变成“已借出”4、归还书籍 :归还成功后书籍的借阅状态会更改成“未借出”,可再次被借阅
2、分析过程,拆解项目
既然我们今天的主题是类,我们就只用面向对象编程来完成这个程序。
类的两种用法
第一种用法是使用类生成实例对象。类作为实例对象的模版,每个实例创建后,都将拥有类的所有属性和方法。
1.查询所有图书
为了让类的结构更清晰,我们可以将这个选择菜单也封装成一个方法menu(),方便调用其他方法。
那么,将上述要编写的两个类整理一下,这个程序的骨架就是这样:(注释里对应每个方法的功能)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Book : def __init__ (self ): class BookManager : def menu (self ): def show_all_book (self ): def add_book (self ): def lend_book (self ): def return_book (self ):
3、代码实现,逐步执行 3.1、定义Book类 根据需求,每本书的基本属性都要有四个:书名、作家、推荐语和借阅状态。所以,我们可以利用初始化方法__init__,让实例被创建时自动获得这些属性。
1 2 3 4 5 6 7 8 9 10 11 12 13 class Book : def __init__ (self, name, author, comment, state=0 ): self.name = name self.author = author self.comment = comment self.state = state book = Book('看不见的城市' , '卡尔维诺' , '献给城市的最后一首爱情诗' ) print (book.author)
为了后续方便参数传递,借阅状态state采用默认参数,用0 来表示’未借出’,1 来表示’已借出’。Book 类还需不需要其他方法。
我们希望的格式是这样的:
1 2 名称:《像自由一样美丽》 作者:林达 推荐语:你要用光明来定义黑暗,用黑暗来定义光明。 状态:未借出
那么,我们可以在初始化方法的基础上定义一个show_info()方法,打印出每本书的信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Book : def __init__ (self, name, author, comment, state=0 ): self.name = name self.author = author self.comment = comment self.state = state def show_info (self ): if self.state == 0 : status = '未借出' else : status = '已借出' return f'名称: 《{self.name} 》\n 作者: {self.author} \n 推荐语:{self.comment} \n 状态: {status} ' book = Book('看不见的城市' , '卡尔维诺' , '献给城市的最后一首爱情诗' ) print (book.show_info())
不过这里老师要介绍一个更符合编程习惯的方法__str__(self)。
在Python中,如果方法名形式是左右带双下划线的,那么就属于特殊方法(如初始化方法),有着特殊的功能。__str__(self)方法,那么当使用print打印实例对象的时候,就会直接打印出在这个方法中return的数据。show_info(self)替换成__str__(self),留意最后一行调用的代码,然后点击运行:
推荐写法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Book : def __init__ (self, name, author, comment, state=0 ): self.name = name self.author = author self.comment = comment self.state = state def __str__ (self ): if self.state == 0 : status = '未借出' else : status = '已借出' return f'名称: 《{self.name} 》\n 作者: {self.author} \n 推荐语:{self.comment} \n 状态: {status} ' book = Book('像自由一样美丽' ,'林达' ,'你要用光明来定义黑暗,用黑暗来定义光明' ) print (book)
可见,打印的结果是一模一样的,区别就是__str__打印对象即可打印出该方法中的返回值,而无须再调用方法。
3.2、类BookManager的编写 3.2.1、定义的结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class BookManager : def menu (self ): def show_all_book (self ): def add_book (self ): def lend_book (self ): def return_book (self ):
menu()是与用户互动的界面,刚刚我们已经给出了demo:
1.查询所有图书
用户输入数字执行相应的功能,程序内部调用的逻辑应该是:
1.查询所有书籍
请输入数字选择对应的功能:
显然,这里需要用到多层条件判断语句。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class BookManager : def menu (self ): print ('欢迎使用流浪图书管理系统,每本沉默的好书都是一座流浪的岛屿,希望你有缘发现并着陆,为精神家园找到一片栖息地。\n' ) while True : print ('1.查询所有书籍\n2.添加书籍\n3.借阅书籍\n4.归还书籍\n5.退出系统\n' ) choice = int (input ('请输入数字选择对应的功能:' )) if choice == 1 : self.show_all_book() elif choice == 2 : self.add_book() elif choice == 3 : self.lend_book() elif choice == 4 : self.return_book() elif choice == 5 : print ('感谢使用!愿你我成为爱书之人,在茫茫书海里相遇。' ) break
3.2.3、【查询所有书籍】show_all_book() 它的功能是打印出系统里所有书籍的信息。
创建Book类的实例对象 为了方便调试,验证代码是否写对了,我们可以先往书籍系统里添加几本书籍.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Book : def __init__ (self, name, author, comment, state = 0 ): self.name = name self.author = author self.comment = comment self.state = state def __str__ (self ): if self.state == 0 : status = '未借出' else : status = '已借出' return '名称:《%s》 作者:%s 推荐语:%s\n状态:%s ' % (self.name, self.author, self.comment, status) class BookManager : def __init__ (self ): book1 = Book('惶然录' ,'费尔南多·佩索阿' ,'一个迷失方向且濒于崩溃的灵魂的自我启示,一首对默默无闻、失败、智慧、困难和沉默的赞美诗。' ) book2 = Book('以箭为翅' ,'简媜' ,'调和空灵文风与禅宗境界,刻画人间之缘起缘灭。像一条柔韧的绳子,情这个字,不知勒痛多少人的心肉。' ) book3 = Book('心是孤独的猎手' ,'卡森·麦卡勒斯' ,'我们渴望倾诉,却从未倾听。女孩、黑人、哑巴、醉鬼、鳏夫的孤独形态各异,却从未退场。' , 1 ) manager = BookManager()
上面的代码,在BookManager类的初始化方法中创建了3个Book类的实例对象。换言之,当创建实例manager时,book1、book2、book3就会生成。
当有多个对象的时候,就要考虑数据存储的方式。由于每个Book实例是并列平行的关系,所以可以用列表来存储。
于是可以在类的开头定义一个空列表books,方便其他方法调用,然后把刚刚创建的Book实例添加到这个列表里。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class BookManager : books = [] def __init__ (self ): book1 = Book('惶然录' ,'费尔南多·佩索阿' ,'一个迷失方向且濒于崩溃的灵魂的自我启示,一首对默默无闻、失败、智慧、困难和沉默的赞美诗。' ) book2 = Book('以箭为翅' ,'简媜' ,'调和空灵文风与禅宗境界,刻画人间之缘起缘灭。像一条柔韧的绳子,情这个字,不知勒痛多少人的心肉。' ) book3 = Book('心是孤独的猎手' ,'卡森·麦卡勒斯' ,'我们渴望倾诉,却从未倾听。女孩、黑人、哑巴、醉鬼、鳏夫的孤独形态各异,却从未退场。' , 1 ) self.books.append(book1) self.books.append(book2) self.books.append(book3)
列表books里的每个元素都是基于Book类创建的实例对象,所以每个元素会自动拥有Book类的方法__str__。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Book : def __init__ (self, name, author, comment, state = 0 ): self.name = name self.author = author self.comment = comment self.state = state def __str__ (self ): status = '未借出' if self.state == 1 : status = '已借出' return '名称:《%s》 作者:%s 推荐语:%s\n状态:%s ' % (self.name, self.author, self.comment, status) class BookManager : books = [] def __init__ (self ): book1 = Book('惶然录' ,'费尔南多·佩索阿' ,'一个迷失方向且濒于崩溃的灵魂的自我启示,一首对默默无闻、失败、智慧、困难和沉默的赞美诗。' ) book2 = Book('以箭为翅' ,'简媜' ,'调和空灵文风与禅宗境界,刻画人间之缘起缘灭。像一条柔韧的绳子,情这个字,不知勒痛多少人的心肉。' ) book3 = Book('心是孤独的猎手' ,'卡森·麦卡勒斯' ,'我们渴望倾诉,却从未倾听。女孩、黑人、哑巴、醉鬼、鳏夫的孤独形态各异,却从未退场。' ,1 ) self.books.append(book1) self.books.append(book2) self.books.append(book3) manager = BookManager() print (len (manager.books))for book in manager.books: print (book)
验证成功。book1,book2,book3,都是Book类的实例对象。又因为对象本身有__str__方法,所以当打印对象时,就会打印出该方法中的返回值。
这个结果和我们想要定义的显示书籍信息的方法show_all_book()是一样的,所以我们可以把最后几行代码封装成方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class BookManager : books = [] def __init__ (self ): book1 = Book('惶然录' ,'费尔南多·佩索阿' ,'一个迷失方向且濒于崩溃的灵魂的自我启示,一首对默默无闻、失败、智慧、困难和沉默的赞美诗。' ) book2 = Book('以箭为翅' ,'简媜' ,'调和空灵文风与禅宗境界,刻画人间之缘起缘灭。像一条柔韧的绳子,情这个字,不知勒痛多少人的心肉。' ) book3 = Book('心是孤独的猎手' ,'卡森·麦卡勒斯' ,'我们渴望倾诉,却从未倾听。女孩、黑人、哑巴、醉鬼、鳏夫的孤独形态各异,却从未退场。' ,1 ) self.books.append(book1) self.books.append(book2) self.books.append(book3) def menu (self ): print ('欢迎使用流浪图书管理系统,每本沉默的好书都是一座流浪的岛屿,希望你有缘发现并着陆,为精神家园找到一片栖息地。\n' ) while True : print ('1.查询所有书籍\n2.添加书籍\n3.借出书籍\n4.归还书籍\n5.退出系统\n' ) choice = int (input ('请输入数字选择对应的功能:' )) if choice == 1 : self.show_all_book() def show_all_book (self ): for book in self.books: print (book) manager = BookManager() manager.menu()
代码合并
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class Book : def __init__ (self, name, author, comment, state = 0 ): self.name = name self.author = author self.comment = comment self.state = state def __str__ (self ): status = '未借出' if self.state == 1 : status = '已借出' return '名称:《%s》 作者:%s 推荐语:%s\n状态:%s ' % (self.name, self.author, self.comment, status) class BookManager : books = [] def __init__ (self ): book1 = Book('惶然录' ,'费尔南多·佩索阿' ,'一个迷失方向且濒于崩溃的灵魂的自我启示,一首对默默无闻、失败、智慧、困难和沉默的赞美诗。' ) book2 = Book('以箭为翅' ,'简媜' ,'调和空灵文风与禅宗境界,刻画人间之缘起缘灭。像一条柔韧的绳子,情这个字,不知勒痛多少人的心肉。' ) book3 = Book('心是孤独的猎手' ,'卡森·麦卡勒斯' ,'我们渴望倾诉,却从未倾听。女孩、黑人、哑巴、醉鬼、鳏夫的孤独形态各异,却从未退场。' ,1 ) self.books.append(book1) self.books.append(book2) self.books.append(book3) def menu (self ): print ('欢迎使用流浪图书管理系统,每本沉默的好书都是一座流浪的岛屿,希望你有缘发现并着陆,为精神家园找到一片栖息地。\n' ) while True : print ('1.查询所有书籍\n2.添加书籍\n3.借出书籍\n4.归还书籍\n5.退出系统\n' ) choice = int (input ('请输入数字选择对应的功能:' )) if choice == 1 : self.show_all_book() break def show_all_book (self ): for book in self.books: print (book) print ('' ) manager = BookManager() manager.menu()
3.2.4、【添加书籍】add_book() 代码结构应该是这样的:当输入数字2的时候,就会跳转到对应的方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class BookManager : books = [] def __init__ (self ): book1 = Book('惶然录' ,'费尔南多·佩索阿' ,'一个迷失方向且濒于崩溃的灵魂的自我启示,一首对默默无闻、失败、智慧、困难和沉默的赞美诗。' ) book2 = Book('以箭为翅' ,'简媜' ,'调和空灵文风与禅宗境界,刻画人间之缘起缘灭。像一条柔韧的绳子,情这个字,不知勒痛多少人的心肉。' ) book3 = Book('心是孤独的猎手' ,'卡森·麦卡勒斯' ,'我们渴望倾诉,却从未倾听。女孩、黑人、哑巴、醉鬼、鳏夫的孤独形态各异,却从未退场。' ,1 ) self.books.append(book1) self.books.append(book2) self.books.append(book3) def menu (self ): print ('欢迎使用流浪图书管理系统,每本沉默的好书都是一座流浪的岛屿,希望你有缘发现并着陆,为精神家园找到一片栖息地。\n' ) while True : print ('1.查询所有书籍\n2.添加书籍\n3.借阅书籍\n4.归还书籍\n5.退出系统\n' ) choice = int (input ('请输入数字选择对应的功能:' )) if choice == 1 : self.show_all_book() elif choice == 2 : self.add_book() def show_all_book (self ): for book in self.books: print (book) def add_book (self ): manager = BookManager() manager.menu()
在下面代码的基础上补充好add_book(self)的代码,尝试录入一本你喜欢的书,再跳回到查询功能,看是否运行成功。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Book : def __init__ (self, name, author, comment, state = 0 ): self.name = name self.author = author self.comment = comment self.state = state class BookManager : books = [] def add_book (self ): new_name = input ('请输入书籍名称:' ) new_author = input ('请输入作者名称:' ) new_comment = input ('请输入书籍推荐语:' ) new_book = Book(new_name, new_author, new_comment) self.books.append(new_book) print ('书籍录入成功!\n' ) manager = BookManager() manager.add_book()
如果注释没有看懂,可以结合下面的数据流转图再理解一下:
3.2.5、【借阅书籍】lend_book() 我们把之前写好的代码整合在一起。虽然代码会越来越长,但都是你已经掌握了的,莫慌!一个函数一个函数看就好了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 class Book : def __init__ (self, name, author, comment, state = 0 ): self.name = name self.author = author self.comment = comment self.state = state def __str__ (self ): status = '未借出' if self.state == 1 : status = '已借出' return '名称:《%s》 作者:%s 推荐语:%s\n状态:%s ' % (self.name, self.author, self.comment, status) class BookManager : books = [] def __init__ (self ): book1 = Book('惶然录' ,'费尔南多·佩索阿' ,'一个迷失方向且濒于崩溃的灵魂的自我启示,一首对默默无闻、失败、智慧、困难和沉默的赞美诗。' ) book2 = Book('以箭为翅' ,'简媜' ,'调和空灵文风与禅宗境界,刻画人间之缘起缘灭。像一条柔韧的绳子,情这个字,不知勒痛多少人的心肉。' ) book3 = Book('心是孤独的猎手' ,'卡森·麦卡勒斯' ,'我们渴望倾诉,却从未倾听。女孩、黑人、哑巴、醉鬼、鳏夫的孤独形态各异,却从未退场。' ,1 ) self.books.append(book1) self.books.append(book2) self.books.append(book3) def menu (self ): print ('欢迎使用流浪图书管理系统,每本沉默的好书都是一座流浪的岛屿,希望你有缘发现并着陆,为精神家园找到一片栖息地。\n' ) while True : print ('1.查询所有书籍\n2.添加书籍\n3.借阅书籍\n4.归还书籍\n5.退出系统\n' ) choice = int (input ('请输入数字选择对应的功能:' )) if choice == 1 : self.show_all_book() elif choice == 2 : self.add_book() elif choice == 3 : self.lend_book() def show_all_book (self ): for book in self.books: print (book) def add_book (self ): new_name = input ('请输入书籍名称:' ) new_author = input ('请输入作者名称:' ) new_comment = input ('请输入书籍推荐语:' ) new_book = Book(new_name, new_author, new_comment) self.books.append(new_book) print ('书籍录入成功!\n' ) def lend_book (self ):
现在,想一想:借阅功能lend_book()要怎么实现呢?可以先想想我们平时找人借东西,会出现哪几种情况?
应该逃不出这几种:1.TA压根没这个东西;2.TA有这个东西,但是被借走了;3.TA有这个东西,借给我们了;4. TA不想借给我们。
在这个项目里,第四种情况可以忽略不计。所以,整理一下思路:
这里有两个要点:1. 怎么判断这本书在不在系统里;2.怎么判断这本书有没有被借走。
首先,判断在不在系统里,我们可以采用遍历书籍列表books的方式,一旦输入的书籍名称和列表元素中的书籍名称出现匹配,就证明系统里有这本书。
其次,如果书在系统里,有没有被借走可以根据实例属性state来判断,0表示’未借出’,1表示’已借出’。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class BookManager : books = [] def __init__ (self ): book1 = Book('惶然录' ,'费尔南多·佩索阿' ,'一个迷失方向且濒于崩溃的灵魂的自我启示,一首对默默无闻、失败、智慧、困难和沉默的赞美诗。' ) book2 = Book('以箭为翅' ,'简媜' ,'调和空灵文风与禅宗境界,刻画人间之缘起缘灭。像一条柔韧的绳子,情这个字,不知勒痛多少人的心肉。' ) book3 = Book('心是孤独的猎手' ,'卡森·麦卡勒斯' ,'我们渴望倾诉,却从未倾听。女孩、黑人、哑巴、醉鬼、鳏夫的孤独形态各异,却从未退场。' ,1 ) self.books.append(book1) self.books.append(book2) self.books.append(book3) def lend_book (self ): borrow_name = input ('请输入你想借阅的书籍名称:' ) for book in self.books: if book.name == borrow_name: if book.state == 1 : print ('你来晚一步,这本书已经被借走了噢' ) break else : print ('借阅成功!借了不看会变胖噢~' ) book.state = 1 break else : continue else : print ('这本书暂时没有收录在系统里呢' )
注意这里有几个层级的else语句,我们可以看到最外层结构是for...else,表示的是当for循环里的对象都遍历完毕后,才执行else子句的内容。
也就是说,当列表里没有对象能够满足if book.name == borrow_name条件时,才会打印else子句的那一句话。(如果for循环内部有break子句,也不会执行)
代码是完成了,但归还书籍的时候,也会碰到类似的逻辑。为了不写重复的代码,我们可以额外在类中定义一个方法,专门检查输入的书名是否在书籍列表里。
换句话说:将上面lend_book()方法中检测书名的代码抽出来,封装成一个函数。这样就可以在借书和还书的代码里直接调用,不用两处重复写同样的代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class BookManager : books = [] name = input ('请输入书籍名称:' ) def check_book (self, name ): for book in self.books: if book.name == name: return book else : return None
为什么要分别返回书籍名称和None值呢?相信你读完下面的代码,就可以理解了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class BookManager : books = [] def check_book (self,name ): for book in self.books: if book.name == name: return book else : return None def lend_book (self ): name = input ('请输入书籍的名称:' ) res = self.check_book(name) if res != None : if res.state == 1 : print ('你来晚了一步,这本书已经被借走了噢' ) else : print ('借阅成功,借了不看会变胖噢~' ) res.state = 1 else : print ('这本书暂时没有收录在系统里呢' )
整合代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 class Book : def __init__ (self, name, author, comment, state = 0 ): self.name = name self.author = author self.comment = comment self.state = state def __str__ (self ): status = '未借出' if self.state == 1 : status = '已借出' return '名称:《%s》 作者:%s 推荐语:%s\n状态:%s ' % (self.name, self.author, self.comment, status) class BookManager : books = [] def __init__ (self ): book1 = Book('惶然录' ,'费尔南多·佩索阿' ,'一个迷失方向且濒于崩溃的灵魂的自我启示,一首对默默无闻、失败、智慧、困难和沉默的赞美诗。' ) book2 = Book('以箭为翅' ,'简媜' ,'调和空灵文风与禅宗境界,刻画人间之缘起缘灭。像一条柔韧的绳子,情这个字,不知勒痛多少人的心肉。' ) book3 = Book('心是孤独的猎手' ,'卡森·麦卡勒斯' ,'我们渴望倾诉,却从未倾听。女孩、黑人、哑巴、醉鬼、鳏夫的孤独形态各异,却从未退场。' ,1 ) self.books.append(book1) self.books.append(book2) self.books.append(book3) def menu (self ): print ('欢迎使用流浪图书管理系统,每本沉默的好书都是一座流浪的岛屿,希望你有缘发现并着陆,为精神家园找到一片栖息地。\n' ) while True : print ('1.查询所有书籍\n2.添加书籍\n3.借出书籍\n4.归还书籍\n5.退出系统\n' ) choice = int (input ('请输入数字选择对应的功能:' )) if choice == 1 : self.show_all_book() elif choice == 2 : self.add_book() elif choice == 3 : self.lend_book() elif choice == 4 : self.return_book() elif choice == 5 : print ('感谢使用!' ) break def show_all_book (self ): for book in self.books: print (book) print ('' ) def add_book (self ): new_name = input ('请输入书籍名称:' ) new_author = input ('请输入作者名称:' ) new_comment = input ('请输入书籍推荐语:' ) new_book = Book(new_name, new_author, new_comment) self.books.append(new_book) print ('书籍录入成功!\n' ) def check_book (self,name ): for book in self.books: if book.name == name: return book else : return None def lend_book (self ): name = input ('请输入书籍的名称:' ) res = self.check_book(name) if res != None : if res.state == 1 : print ('你来晚了一步,这本书已经被借走了噢' ) else : print ('借阅成功,借了不看会变胖噢~' ) res.state = 1 else : print ('这本书暂时没有收录在系统里呢' ) manager = BookManager() manager.menu()
3.2.6、【归还书籍】return_book() 现在只剩下归还图书return_book这一功能了,它和lend_book有着异曲同工之妙,也是调用check_book方法进行判断。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 class Book : def __init__ (self, name, author, comment, state = 0 ): self.name = name self.author = author self.comment = comment self.state = state def __str__ (self ): status = '未借出' if self.state == 1 : status = '已借出' return '名称:《%s》 作者:%s 推荐语:%s\n状态:%s ' % (self.name, self.author, self.comment, status) class BookManager : books = [] def __init__ (self ): book1 = Book('惶然录' ,'费尔南多·佩索阿' ,'一个迷失方向且濒于崩溃的灵魂的自我启示,一首对默默无闻、失败、智慧、困难和沉默的赞美诗。' ) book2 = Book('以箭为翅' ,'简媜' ,'调和空灵文风与禅宗境界,刻画人间之缘起缘灭。像一条柔韧的绳子,情这个字,不知勒痛多少人的心肉。' ) book3 = Book('心是孤独的猎手' ,'卡森·麦卡勒斯' ,'我们渴望倾诉,却从未倾听。女孩、黑人、哑巴、醉鬼、鳏夫的孤独形态各异,却从未退场。' ,1 ) self.books.append(book1) self.books.append(book2) self.books.append(book3) def menu (self ): print ('欢迎使用流浪图书管理系统,每本沉默的好书都是一座流浪的岛屿,希望你有缘发现并着陆,为精神家园找到一片栖息地。\n' ) while True : print ('1.查询所有书籍\n2.添加书籍\n3.借阅书籍\n4.归还书籍\n5.退出系统\n' ) choice = int (input ('请输入数字选择对应的功能:' )) if choice == 1 : self.show_all_book() elif choice == 2 : self.add_book() elif choice == 3 : self.lend_book() elif choice == 4 : self.return_book() elif choice == 5 : print ('感谢使用!愿你我成为爱书之人,在茫茫书海里相遇。' ) break def show_all_book (self ): print ('书籍信息如下:' ) for book in self.books: print (book) print ('' ) def add_book (self ): new_name = input ('请输入书籍名称:' ) new_author = input ('请输入作者名称:' ) new_comment = input ('请输入书籍推荐语:' ) new_book = Book(new_name, new_author, new_comment) self.books.append(new_book) print ('书籍录入成功!\n' ) def check_book (self,name ): for book in self.books: if book.name == name: return book else : return None def lend_book (self ): name = input ('请输入书籍的名称:' ) res = self.check_book(name) if res != None : if res.state == 1 : print ('你来晚了一步,这本书已经被借走了噢' ) else : print ('借阅成功,借了不看会变胖噢~' ) res.state = 1 else : print ('这本书暂时没有收录在系统里呢' ) def return_book (self ): name = input ('请输入归还书籍的名称:' ) res = self.check_book(name) if res == None : print ('没有这本书噢,你恐怕输错了书名~' ) else : if res.state == 0 : print ('这本书没有被借走,在等待有缘人的垂青呢!' ) else : print ('归还成功!' ) res.state = 0 manager = BookManager() manager.menu()
第15关 编码和文件读写 1、编码 我们先来看编码。编码的本质就是让只认识0和1的计算机,能够理解我们人类使用的语言符号,并且将数据转换为二进制进行存储和传输。
1.1、二进制 假设我们都是看守城墙的小兵,你在烽火台A上,我在烽火台B上,只要你那边来了敌人,你就点着烽火台通知我。
如果只有一个烽火台,那么只有“点着火”和“没点火”两种状态,这就像电子元件里“通电”和“没通电”的状态,所以只有0和1.
现在有两座烽火台,右边为第1座,左边为第2座。我们约定,当没有烽火台被点着的时候,表示没有敌人(00);只点着第一座烽火台的时候,表示来了一个敌人(01);只点着第二座烽火台的时候,表示来了2个敌人。(10,逢二进一)
二进制 - 十进制
所以两个二进制位可以表示十进制的0,1,2,3 四种状态。
我们继续往下推,当有三座烽火台的时候,我们可以表示0~7 八种状态(也就是2的3次方)。
当有八座烽火台的时候,我们就能表示2的8次方,也就是256种状态,它由8个0或1组成。
00000000 表示状态0: 烽火全暗,一个敌人没有,平安无事,放心睡觉。
用来存放一位0或1,就是计算机里最小的存储单位,叫做【位】,也叫【比特】(bit)。我们规定8个比特构成一个【字节】(byte),这是计算机里最常用的单位。
而百兆宽带,下载速度最多能达到十多兆,是因为运营商的带宽是以比特每秒 为单位的,比如100M就是100Mbit/s。
而我们常看到的下载速度KB却是以字节每秒 为单位显示的,1byte = 8bit,所以运营商说的带宽得先除以8,你的百兆宽带下载速度,也就是十几兆了。
1.2、编码表 Unicode (万国码)应运而生,这套编码表将世界上所有的符号都纳入其中。每个符号都有一个独一无二的编码,现在Unicode可以容纳100多万个符号,所有语言都可以互通,一个网页上也可以显示多国语言。
UTF-8 (8-bit Unicode Transformation Format)。它是一种针对Unicode 的可变长度字符编码,它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,而当字符在ASCII 码的范围时,就用一个字节表示,所以UTF-8还可以兼容ASCII编码。
Unicode 是内存编码的规范,而UTF-8 是如何保存和传输Unicode的手段。
1.3、encode()和decode() 编码,即将人类语言转换为计算机语言,就是【编码】**encode();反之,就是【解码】 decode()**。
1 2 3 4 print ('吴枫' .encode('utf-8' ))print ('吴枫' .encode('gbk' ))print (b'\xe5\x90\xb4\xe6\x9e\xab' .decode('utf-8' ))print (b'\xce\xe2\xb7\xe3' .decode('gbk' ))
将人类语言编码后得到的结果,有一个相同之处,就是最前面都有一个字母b ,比如**b’\xce\xe2\xb7\xe3’,这代表它是bytes(字节)类型的数据。我们可以用 type()**函数验证一下
1 2 print (type ('吴枫' ))print (type (b'\xce\xe2\xb7\xe3' ))
所谓的编码,其实本质就是把str(字符串)类型的数据,利用不同的编码表,转换成bytes(字节)类型的数据。
字符是人们使用的记号,一个抽象的符号,这些都是字符:**’1’, ‘中’, ‘a’, ‘$’, ‘¥’** 。
字节则是计算机中存储数据的单元,一个8位的二进制数。
\x 是分隔符,用来分隔一个字节和另一个字节。
%,它们也是分隔符,替换了Python中的 \x 。
1 2 \xe5\x90\xb4\xe6\x9e\xab %E5%90 %B4%E6%9E%AB
用**decode()**解码的时候则要注意,UTF-8编码的字节就一定要用UTF-8的规则解码,其他编码同理,否则就会出现乱码或者报错的情况。
我们再来看下ASCII 编码,它不支持中文,所以我们来转换一个大写英文字母K 。
1 print ('K' .encode('ASCII' ))
你看到大写字母K被编码后还是K,但这两个K对计算机来说意义是不同的。前者是字符串,采用系统默认的Unicode编码,占两个字节。后者则是bytes类型的数据,只占一个字节。这也验证我们前面所说的编码就是将str类型转换成bytes类型。
2、文件读写 2.1、读取文件 三步:
打开文件——读文件——关闭文件 【第1步-开】 使用**open()**函数打开文件。语法是这样的:
1 file1 = open ('/Users/Ted/Desktop/test/abc.txt' ,'r' ,encoding='utf-8' )
**open()**函数里面有三个参数 第一个参数是文件的保存地址,一定要写清楚,否则计算机找不到。
绝对路径 就是最完整的路径,
相对路径 指的就是【相对于当前文件夹】的路径,也就是你编写的这个py文件所放的文件夹路径!
Windows系统里,常用*\*来表示绝对路径, /**来表示相对路径
1 2 3 4 5 open ('C:\\Users\\Ted\\Desktop\\test\\abc.txt' )open (r'C:\Users\Ted\Desktop\test\abc.txt' )
第二个参数表示打开文件时的模式。这里是字符串 ‘r’,表示 read,表示我们以 读 的模式打开了这个文件。 除了**’r’,其他还有 ‘w’(写入), ‘a’**(追加)等模式,我们稍后会涉及到。
第三个参数encoding=’utf-8’,表示的是返回的数据采用何种编码,一般采用utf-8或者gbk。注意这里是写 encoding 而不是encode 噢。 【第2步-读】 打开文件file1 之后,就可以用**read()**函数进行读取的操作了。请看代码:
1 2 3 file1 = open ('/Users/Ted/Desktop/test/abc.txt' ,'r' ,encoding='utf-8' ) filecontent = file1.read() print (filecontent)
第2行代码就是在读取file1的内容,写法是变量file1 后面加个**.句点,再加个 read(),并且把读到的内容放在变量 filecontent**里面,这样我们才能拿到文件的内容。
【第3步-关】 关闭文件,使用的是**close()**函数。
1 2 3 4 file1 = open ('/Users/Ted/Desktop/test/abc.txt' ,'r' ,encoding='utf-8' ) filecontent = file1.read() print (filecontent)file1.close()
变量file1后面加个点,然后再加个close(),就代表着关闭文件。千万要记得后面的括号可不能丢。
为啥要关闭文件呢?原因有两个:1.计算机能够打开的文件数量是有限制的,open()过多而不close()的话,就不能再打开文件了。2.能保证写入的内容已经在文件里被保存好了。
2.2、写入文件 三步:
打开文件——写入文件——关闭文件 【第1步-开】 以写入的模式打开文件。
1 2 file1 = open ('/Users/Ted/Desktop/test/abc.txt' ,'w' ,encoding='utf-8' )
第1行代码:以写入的模式打开了文件”abc.txt”。
open() 中还是三个参数,其他都一样,除了要把第二个参数改成**’w’**,表示write,即以写入的模式打开文件。
【第2步-写】 往文件中写入内容,使用**write()**函数。
1 2 3 file1 = open ('/Users/Ted/Desktop/test/abc.txt' , 'w' ,encoding='utf-8' ) file1.write('张无忌\n' ) file1.write('宋青书\n' )
第2-3行代码:往“abc.txt”文件中写入了“张无忌”和“宋青书”这两个字符串。\n 表示另起一行。
诶?原来文件里的周芷若和赵敏去哪里了?
是这样子的,**’w’写入模式会给你暴力清空掉文件,然后再给你写入。如果你只想增加东西,而不想完全覆盖掉原文件的话,就要使用 ‘a’**模式,表示append,你学过,它是追加的意思。
1 2 3 4 5 6 file1 = open ('/Users/Ted/Desktop/test/abc.txt' , 'a' ,encoding='utf-8' ) file1.write('张无忌\n' ) file1.write('宋青书\n' )
【第3步-关】 还是要记得关闭文件,使用**close()**函数。
1 2 3 4 file1 = open ('/Users/Ted/Desktop/test/abc.txt' ,'a' ,encoding='utf-8' ) file1.write('张无忌\n' ) file1.write('宋青书\n' ) file1.close()
有两个小提示:1.**write()函数写入文本文件的也是字符串类型。2.在 ‘w’和 ‘a’模式下,如果你打开的文件不存在,那么 open()**函数会自动帮你创建一个。
【练习时间来咯】1.请你在一个叫1.txt 文件里写入字符串**’难念的经’** 2.然后请你读取这个1.txt 文件的内容,并打印出来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 f1 = open ('./1.txt' ,'a' ,encoding='utf-8' ) f1.write('难念的经' ) f1.close() f2 = open ('./1.txt' ,'r' ,encoding='utf-8' ) content = f2.read() print (content)f2.close()
如果我们想写入的数据不是文本内容,而是音频和图片的话,该怎么做呢?
我们可以看到里面有**’wb’**的模式,它的意思是以二进制的方式打开一个文件用于写入。因为图片和音频是以二进制的形式保存的,所以使用wb模式就好了。
为了避免打开文件后忘记关闭,占用资源或当不能确定关闭文件的恰当时机的时候,我们可以用到关键字with。
1 2 3 4 5 6 7 8 9 10 11 12 file1 = open ('abc.txt' ,'a' ) file1.write('张无忌' ) file1.close() with open ('abc.txt' ,'a' ) as file1: file1.write('张无忌' )
2.3、小练习 现在假设你来到了魔法世界,最近期末快到了,霍格沃兹魔法学校准备统计一下大家的成绩。
评选的依据是什么呢?就是同学们平时的作业成绩。
现在有这样一个叫scores.txt 的文件,里面有赫敏、哈利、罗恩、马尔福四个人的几次魔法作业的成绩。
这里是文件内容,你可以在自己的电脑里新建一个scores.txt 来操作。
罗恩 23 35 44
希望你来统计这四个学生的魔法作业的总得分,然后再写入一个txt文件。注意,这个练习的全程只能用Python。
好,一个非常粗糙的思路应该是:拿到txt文件里的数据,然后对数据进行统计,然后再写入txt文件。好,马上开始。
首先,毫无疑问,肯定是打开文件,还记得用什么函数吗?
1 file1 = open ('/Users/Ted/Desktop/scores.txt' ,'r' ,encoding='utf-8' )
接着呢,就是读取文件了。一般来说,我们是用**read()**函数,但是在这里,我们是需要把四个人的数据分开处理的,我们想要按行处理,而不是一整个处理,所以读的时候也希望逐行读取。
因此,我们需要使用一个新函数**readlines()**,也就是“按行读取”。
1 2 3 4 file1 = open ('/Users/Ted/Desktop/scores.txt' ,'r' ,encoding='utf-8' ) file_lines = file1.readlines() file1.close() print (file_lines)
你看到了,readlines() 会从txt文件取得一个列表,列表中的每个字符串就是scores.txt 中的每一行。而且每个字符串后面还有换行的\n 符号。
这样一来,我们就可以使用for循环 来遍历这个列表,然后处理列表中的数据,请看第五行代码:
1 2 3 4 5 6 file1 = open ('/Users/Ted/Desktop/scores.txt' ,'r' ,encoding='utf-8' ) file_lines = file1.readlines() file1.close() for i in file_lines: print (i)
好,现在我们要把这里每一行的名字、分数也分开,这时需要我们使用**split()**来把字符串分开,它会按空格把字符串里面的内容分开。
1 2 3 4 5 6 7 file1 = open ('/Users/Ted/Desktop/scores.txt' ,'r' ,encoding='utf-8' ) file_lines = file1.readlines() file1.close() for i in file_lines: data =i.split() print (data)
**split()是把字符串分割的,而还有一个 join()**函数,是把字符串合并的。
1 2 3 4 5 a=['c' ,'a' ,'t' ] b='' print (b.join(a))c='-' print (c.join(a))
**join()的用法是 str.join(sequence)**,str代表在这些字符串之中,你要用什么字符串连接,在这里两个例子,一个是空字符串,一个是横杠,sequence代表数据序列,在这里是列表a。
这4个列表的第0个数据是姓名,之后的就是成绩。我们需要先统计各人的总成绩,然后把姓名和成绩放在一起。
还是可以用**for…in…**循环进行加法的操作,请看第8行的代码:
1 2 3 4 5 6 7 8 9 10 11 file1 = open ('/Users/Ted/Desktop/scores.txt' ,'r' ,encoding='utf-8' ) file_lines = file1.readlines() file1.close() for i in file_lines: data =i.split() sum = 0 for score in data[1 :]: sum = sum + int (score) result = data[0 ]+str (sum ) print (result)
好,接下来就是把成绩写入一个空的列表,因为这样才有助于我们之后写入一个txt文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 file1 = open ('/Users/Ted/Desktop/scores.txt' ,'r' ,encoding='utf-8' ) file_lines = file1.readlines() file1.close() final_scores = [] for i in file_lines: data =i.split() sum = 0 for score in data[1 :]: sum = sum + int (score) result = data[0 ]+str (sum )+'\n' final_scores.append(result)
好啦,那我们就已经处理好了,就差写入文件啦。大家可以从第15行开始看:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 file = open ('/Users/Ted/Desktop/scores.txt' ,'r' ,encoding='utf-8' ) file_lines = file.readlines() file.close() final_scores = [] for i in file_lines: data =i.split() sum = 0 for score in data[1 :]: sum = sum + int (score) result = data[0 ]+str (sum )+'\n' final_scores.append(result) winner = open ('/Users/Ted/Desktop/winner.txt' ,'w' ,encoding='utf-8' ) winner.writelines(final_scores) winner.close()
15行的代码是打开一个叫winner.txt 的文件。(如果电脑中不存在winner.txt的话,这行代码会帮你自动新建一个空白的winner.txt)
16行的代码是以writelines()的方式写进去,为什么不能用 write()?因为 final_scores 是一个列表,而**write()的参数必须是一个字符串,而 writelines()可以是序列,所以我们使用 writelines()**。
第16关 模块 1、什么是模块 用书里的话说:模块是最高级别的程序组织单元。这句话的意思是,模块什么都能封装,就像这样:
在模块中,我们不但可以直接存放变量,还能存放函数,还能存放类。
更独特的是,定义变量需要用赋值语句,封装函数需要用def 语句,封装类需要用class 语句,但封装模块不需要任何语句。
之所以不用任何语句,是因为每一份单独的Python代码文件(后缀名是**.py**的文件)就是一个单独的模块。
封装模块的目的也是为了把程序代码和数据存放起来以便再次利用。如果封装成类和函数,主要还是便于自己调用,但封装了模块,我们不仅能自己使用,文件的方式也很容易共享给其他人使用。
test.py
main.py
你看,是不是发现main.py 文件借用并运行了test.py 文件里的代码了?这就是import 语句起作用了。
2、使用自己的模块 2.1、import语句 我们使用import语句导入一个模块,最主要的目的并不是运行模块中的执行语句,而是为了利用模块中已经封装好的变量、函数、类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 a = '我是模块中的变量a' def hi (): a = '我是函数里的变量a' print ('函数“hi”已经运行!' ) class Go2 : a = '我是类2中的变量a' def do2 (self ): print ('函数“do2”已经运行!' ) print (a) hi() A = Go2() print (A.a) A.do2()
麻雀虽小,五脏俱全。这段代码中基本上展现了所有的调用方式。
现在我们要做的是把这段代码拆分成两个模块,把封装好的变量、函数、类,放到test.py 文件中,把执行相关的语句放到main.py 文件中。
test,py
1 2 3 4 5 6 7 8 9 10 a = '我是模块中的变量a' def hi (): a = '我是函数里的变量a' print ('函数“hi”已经运行!' ) class Go2 : a = '我是类2中的变量a' def do2 (self ): print ('函数“do2”已经运行!' )
main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 import test print (test.a) test.hi() A = test.Go2() print (A.a) A.do2()
练习
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 sentence = '从前有座山,' def mountain (): print ('山里有座庙,' ) class Temple : sentence = '庙里有个老和尚,' def reading (self ): print ('在讲一个长长的故事。' ) for i in range (10 ): print (sentence) mountain() A = Temple() print (A.sentence) A.reading() print ()
请你把这段代码拆分到两个模块中,其中执行语句放到main.py 文件,封装好的变量、函数和类放到story.py 文件。
story.py
1 2 3 4 5 6 7 8 9 sentence = '从前有座山,' def mountain (): print ('山里有座庙,' ) class Temple : sentence = '庙里有个老和尚,' def reading (self ): print ('在讲一个长长的故事。' )
main.py
1 2 3 4 5 6 7 8 9 import storyfor i in range (10 ): print (story.sentence) story.mountain() A = story.Temple() print (A.sentence) A.reading() print ()
import 语句还有一种用法是import…as… 。比如我们觉得import story 太长,就可以用import story as s 语句,意思是为“story”取个别名为“s”。
1 2 3 4 5 6 7 8 9 10 11 import story as sfor i in range (10 ): print (s.sentence) s.mountain() A = s.Temple() print (A.sentence) A.reading() print ()
另外,当我们需要同时导入多个模块时,可以用逗号隔开。比如import a,b,c 可以同时导入“a.py,b.py,c.py”三个文件。
2.2、from … import … 语句 from … import … 语句可以让你从模块中导入一个指定的部分到当前模块。格式如下:
例子 :
1 2 3 4 5 6 7 def hi (): print ('函数“hi”已经运行!' ) from test import hi hi()
当我们需要从模块中同时导入多个指定内容,也可以用逗号隔开,写成from xx模块 import a,b,c 的形式。我们再运行一个小案例。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 a = '我是模块中的变量a' def hi (): a = '我是函数里的变量a' print ('函数“hi”已经运行!' ) class Go2 : a = '我是类2中的变量a' def do2 (self ): print ('函数“do2”已经运行!' ) from test import a,hi,Go2print (a) hi() A = Go2() print (A.a) A.do2()
对于from … import … 语句要注意的是,没有被写在import 后面的内容,将不会被导入。
当我们需要从模块中指定所有内容直接使用时,可以写成【from xx模块 import *】 的形式,*代表“模块中所有的变量、函数、类”,我们再运行一个小案例。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 a = '我是模块中的变量a' def hi (): a = '我是函数里的变量a' print ('函数“hi”已经运行!' ) class Go2 : a = '我是类2中的变量a' def do2 (self ): print ('函数“do2”已经运行!' ) from test import *print (a) hi() A = Go2() print (A.a) A.do2()
不过,一般情况下,我们不要为了图方便直接使用【from xx模块 import *】的形式。
这是因为,模块.xx 的调用形式能通过阅读代码一眼看出是在调用模块中的变量/函数/方法,而去掉**模块.**后代码就不是那么直观了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 sentence = '从前有座山,' def mountain (): print ('山里有座庙,' ) class Temple : sentence = '庙里有个老和尚,' def reading (self ): print ('在讲一个长长的故事。' ) import storyfor i in range (10 ): print (story.sentence) story.mountain() A = story.Temple() print (A.sentence) A.reading() print ()
要直接使用Temple 类的属性,我们需要在导入的时候指定Temple 类(不能直接指定类属性)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 sentence = '从前有座山,' def mountain (): print ('山里有座庙,' ) class Temple : sentence = '庙里有个老和尚,' def reading (self ): print ('在讲一个长长的故事。' ) from story import Templeprint (Temple.sentence)
2.3、if name == ‘main ‘ 为了解释什么是【if __name__ == '__main__'】,我先给大家讲解一个概念“程序的入口”。
对于Python和其他许多编程语言来说,程序都要有一个运行入口。
在Python中,当我们在运行某一个py文件,就能启动程序 ——— 这个py文件就是程序的运行入口。
但是,当我们有了一大堆py文件组成一个程序的时候,为了【指明】某个py文件是程序的运行入口,我们可以在该py文件中写出这样的代码:
1 2 3 4 5 6 代码块 ①…… if __name__ == '__main__' : 代码块 ②……
这里的【if __name__ == '__main__'】就相当于是 Python 模拟的程序入口。Python 本身并没有规定这么写,这是一种程序员达成共识的编码习惯。
第一段代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import Ba = '我是模块中的变量a' def hi (): a = '我是函数里的变量a' print ('函数“hi”已经运行!' ) class Go2 : a = '我是类2中的变量a' def do2 (self ): print ('函数“do2”已经运行!' ) print ('【载入模块时,所有语句都会被运行】' )print (a)hi() b = Go2() print (Go2.a)b.do2()
第一段代码没有使用if __name__ == '__main__',所有语句都会被运行。
第二段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import Ba = '我是模块中的变量a' def hi (): a = '我是函数里的变量a' print ('函数“hi”已经运行!' ) class Go1 : a = '我是类1中的变量a' @classmethod def do1 (cls ): print ('函数“do1”已经运行!' ) class Go2 : a = '我是类2中的变量a' def do2 (self ): print ('函数“do2”已经运行!' ) if __name__ == '__main__' : print ('是主模块的时候才会执行以下语句:' ) print (a) hi() b = Go2() print (Go2.a) b.do2()
现在我们运行代码的时候,会发现if __name__ == '__main__'下的语句不会被执行。这是因为B.py 文件并不是我们现在的程序运行入口,它是被A.py 文件导入的。
3、使用他人的模块 这两个例子中的第一句代码import time 和import random 其实就是在导入time 和random 模块。
3.1、初探借用模块 time模块和random模块是Python的系统内置模块,也就是说Python安装后就准备好了这些模块供你使用。
如果是第三方编写的模块,我们需要先从Python的资源管理库下载安装相关的模块文件。
下载安装的方式是打开终端,Windows用户输入pip install + 模块名 ;苹果电脑输入:pip3 install + 模块名 ,点击enter即可。(需要预装python解释器和pip)
random模块
我们熟悉的函数**random.choice(list)**,功能是从列表中随机抽取一个元素并返回。它的代码被找到了:
1 2 3 4 5 6 7 def choice (self, seq ): """Choose a random element from a non-empty sequence.""" try : i = self._randbelow(len (seq)) except ValueError: raise IndexError('Cannot choose from an empty sequence' ) return seq[i]
另一个熟悉的函数**random.randint(a,b)**,功能是在a到b的范围随机抽取一个整数。它的代码也被找到了:
1 2 3 def randint (self, a, b ): """Return random integer in range [a, b], including both end points.""" return self.randrange(a, b+1 )
3.2、如何自学模块 https://docs.python.org/zh-cn/3.12/tutorial/index.html
搜到教程后,我们重点关注的是模块中的函数 和类方法 有什么作用,然后把使用案例做成笔记(还记得第8关谈到的如何做学习笔记么?)。
例如random模块的关键知识(也就是比较有用的函数和类方法),可以做成这样的笔记:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import random a = random.random() print (a)a = random.randint(0 ,100 ) print (a)a = random.choice('abcdefg' ) print (a)a = random.sample('abcdefg' , 3 ) print (a)items = [1 , 2 , 3 , 4 , 5 , 6 ] random.shuffle(items) print (items)
另外,我们还可以使用**dir()**函数查看一个模块,看看它里面有什么变量、函数、类、类方法。
1 2 3 import random print (dir (random))
这就像是查户口一样,可以把模块中的函数(函数和类方法)一览无余地暴露出来。对于查到的结果"__xx__"结构的(如__doc__),它们是系统相关的函数,我们不用理会,直接看全英文的函数名即可。
甚至不是模块,我们也可以用这种方式自学:**dir(x)**,可以查询到x相关的函数,x可以是模块,也可以是任意一种对象。
1 2 3 4 5 6 7 8 9 10 11 a = '' print ('字符串:' )print (dir (a)) a = [] print ('列表:' )print (dir (a)) a = {} print ('字典:' )print (dir (a))
好,我们回到模块上。再次总结一下模块的学习方法,其实可以归纳成三个问题:
这里想提醒大家的是,比较小的模块(比如random模块)可以通过这样的方式自学,大型模块的学习就比较困难(除非你有充足的专业背景知识)。
3.3、学习csv模块 csv是一种文件格式,你可以把它理解成“简易版excel”。学会了csv模块 ,你就可以用程序处理简单的电子表格了。
我们使用import语句导入csv模块,然后用**dir()**函数看看它里面有什么东西:
1 2 3 4 5 6 7 import csvfor i in dir (csv): print (i)
https://docs.python.org/zh-cn/3.12/library/csv.html
如果你要通过阅读这份教程来学习csv模块的话,最简单的方式是先看案例(拉到教程的最后),遇到看不懂的函数,再倒回来查具体使用细节。
读取表格文件
1 2 3 4 5 6 7 8 9 10 11 12 13 import csvwith open ("test.csv" ,newline = '' ,encoding = 'utf-8' ) as f: reader = csv.reader(f) for row in reader: print (row) print ("读取完毕!" )
写入表格文件
先创建一个变量名为writer (也可以是其他名字)的实例,创建方式是writer = csv.writer(x),然后使用 writer.writerow(列表)就可以给csv文件写入一行 列表 中的内容。
另外关于open函数的参数,也就是图中的**’a’**,我们来复习一下:
练习
1 2 3 4 5 import csvwith open ('test.csv' ,'a' , newline='' ,encoding='utf-8' ) as f: writer = csv.writer(f) writer.writerow(['4' , '猫砂' , '25' , '1022' , '886' ]) writer.writerow(['5' , '猫罐头' , '18' , '2234' , '3121' ])
第17关 项目实操:收发邮件 1、明确项目目标 第1个项目目标是:用Python群发邮件。
第2个项目目标是:学会自学新模块。
2、分析过程,拆解项目
版本1.0,主要是根据需求,自己寻找和学习相关的模块,然后给自己发一封最简单的邮件。
版本2.0呢,还是给自己发邮件,但邮件应该更完整,包括邮件头(就是发件人、邮件标题等),和正文内容。
版本3.0呢,主要是从单一收件人,变成多收件人,也就是群发一封完整的邮件。
3、逐步执行,代码实现 3.1、版本1.0:学习模块,发一封简单邮件 其实,只要搜索关键词“发送邮件 python”,就能找到解决方案。
而且还会知道:smtplib 是用来发送邮件用的,email 是用来构建邮件内容的。这两个都是Python内置模块。
总结一下:到底学习什么模块,关键在于你的需求,这样我们才能从需求出发找到对应的解决方案,解决自己的问题。
我们以smtplib模块 为例来实操一下: 对于smtplib模块 ,我们想要去查看它的官方文档,也只需要在浏览器里搜索关键词“smtplib python”就好。
这个文档提供的内容有:需要向smtplib模块输入什么;smtplib模块能做什么;smtplib模块返回的是什么;常见的报错;SMTP对象有哪些方法及如何使用;一个应用实例。
重新搜索一次,关键词换成 “smtplib 教程” ,你就能看到好多好多中国人编写的内容。在可读性上,是要比官方文档好一些的,但缺点在于良莠不齐。你可以自行挑选适合自己的去阅读。
这两个问题就是:
1.这两个模块分别有什么方法,
2.模块的方法怎么用。
总结一下这些内容,如果我们要发送邮件,就需要用到smtplib模块 的以下方法:
1 2 3 4 5 6 7 import smtplibserver = smtplib.SMTP() server.connect(host, port) server.login(username, password) server.sendmail(sender, to_addr, msg.as_string()) server.quit()
第一行,我们懂,是引入smtplib模块 。
第三行,server 是一个变量,smtplib.SMTP()是变量server的值。我们已经知道了 smtplib 是模块的名称,那SMTP 是什么意思呢?
要想调用 smtplib 模块下、SMTP 类下的方法,应该这样写:smtplib.SMTP.方法 。
对,SMTP (Simple Mail Transfer Protocol)翻译过来是“简单邮件传输协议”的意思,SMTP 协议是由源服务器到目的地服务器传送邮件的一组规则。
1 2 3 4 import smtplibserver = smtplib.SMTP() server.connect(host, port)
第四行代码,就是干这个工作的,连接(connect)指定的服务器。
host 是指定连接的邮箱服务器,你可以指定服务器的域名。通过搜索“xx邮箱服务器地址”,就可以找到。
port 是“端口”的意思。端口属于计算机网络知识里的内容,你可以自行搜索了解,现在我们只要知道它是一个【整数】即可。
我们需要指定SMTP 服务使用的端口号,一般情况下SMTP默认端口号为25 。
包括服务器名称,端口和加密方式。服务器名称是mail.forchange.tech ,端口是587 。你可以登录自己的邮箱,查看这些信息,接下来跟着我一起写代码。
现在参数确定了,代码写出来应该长这样:
1 2 3 4 import smtplibserver = smtp.SMTP() server.connect('mail.forchange.tech' ,587 )
这里有两种写法,一是使用默认端口:25。
1 2 3 4 import smtplibserver = smtplib.SMTP() server.connect('smtp.qq.com' , 25 )
二是,尝试搜索到的端口,比如465。这时会有些不同,QQ 邮箱采用的加密方式是SSL,我们需要写成这样:
1 2 3 4 5 6 import smtplibserver = smtplib.SMTP_SSL() server.connect('smtp.qq.com' , 465 )
提醒!QQ 邮箱一般默认关闭SMTP 服务,我们得先去开启它。请打开https://mail.qq.com/,登录你的邮箱。然后点击位于顶部的【设置】按钮,选择【账户设置】,然后下拉到这个位置。
就像上面的一样,把第一项服务打开。需要用密保手机发送短信,完成之后,QQ 邮箱会提供给你一个授权码,授权码的意思是,你可以不用QQ的网页邮箱或者邮箱客户端来登录,而是用邮箱账号+授权码获取邮箱服务器的内容。
如果你打算用QQ邮箱自动发邮件,请保存好这个授权码。在你使用SMTP服务登录邮箱时,要输入这个授权码作为密码登录,而【不是】你的邮箱登录密码。
1 2 3 4 5 6 7 import smtplibserver = smtplib.SMTP() server.connect(host, port) server.login(username, password) server.sendmail(from_addr, to_addr, msg.as_string()) server.quit()
第五行代码,login 是登录的意思,也就是登录你指定的服务器用的,需要输入两个参数:登录邮箱和授权码。
1 2 3 4 5 6 username = 'xxx@qq.com' password = '你的授权码数字' server.login(username, password)
第六行代码sendmail 是“发送邮件”的意思,是发送邮件用的,**sendmail()**方法需要三个参数:发件人,收件人和邮件内容。
这里的发件人from_addr 与上面的username 是一样的,都是你的登录邮箱,所以只用设置一次。
1 2 3 4 5 6 7 from_addr = 'xxx@qq.com' to_addr = 'xxx@qq.com' server.sendmail(from_addr, to_addr, msg.as_string())
最后一行代码,quit 是“退出”的意思,就是退出服务器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import smtplibfrom_addr = 'xxx@qq.com' password = '你的授权码数字' to_addr = 'xxx@qq.com' smtp_server = 'smtp.qq.com' server = smtplib.SMTP_SSL() server.connect(smtp_server,465 ) server.login(from_addr, password) server.sendmail(from_addr, to_addr, msg.as_string()) server.quit()
email 模块 :也就是用来写邮件内容的模块。这个内容可以是纯文本、HTML内容、图片、附件等多种形式。
每种形式对应的导入方式是这样的:
1 2 3 from email.mime.text import MIMETextfrom email.mime.image import MIMEImagefrom email.mime.multipart import MIMEMultipart
请你按住ctrl同时点击mime ,你会看到一个名为*init* .py
这就要谈到“模块”和“包”的区别了,模块(module)一般是一个文件,而包(package)是一个目录,一个包中可以包含很多个模块,可以说包是“模块打包”组成的。
但为什么看到那个空文件,就能知道email是包呢?这是因为Python中的包都必须默认包含一个*init* .py
*init* .pyimport email 是行不通的。
所以,我们就需要使用from … import … 语句,从email包 目录下的【某个文件】引入【需要的对象】。比如从email包 下的text文件 中引入MIMEText方法 。中文说起来有点复杂,看代码就懂了:
1 2 from email.mime.text import MIMEText
下面,我们先从【构建纯文本的邮件内容】开始,也就是我们版本1.0的功能:发一封最简单的一句话文本邮件。
1 2 3 4 MIMEText(msg,type ,chartset)
文本类型和文本编码,我们默认用**’plain’和 ‘utf-8’**。文本内容,我就写一句最简单的“send by python”吧,你可以写自己想写的话啦。
1 2 3 from email.mime.text import MIMETextmsg = MIMEText('send by python' ,'plain' ,'utf-8' )
11
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import smtplibfrom email.mime.text import MIMETextfrom_addr = 'xxx@qq.com' password = '你的授权码数字' to_addr = 'xxx@qq.com' smtp_server = 'smtp.qq.com' msg = MIMEText('send by python' ,'plain' ,'utf-8' ) server = smtplib.SMTP_SSL() server.connect(smtp_server,465 ) server.login(from_addr, password) server.sendmail(from_addr, to_addr, msg.as_string()) server.quit()
例如这个报错信息:ValueError: server_hostname cannot be an empty string or start with a leading dot.
直接在网络搜索这个报错信息,我们会得到结论:如果你的Python版本是3.7,很可能发生这种报错。因为Python 3.7修改了ssl.py,导致smtplib.SMTP_SSL也连带产生了问题。
1 2 3 4 5 server = smtplib.SMTP_SSL() server = smtplib.SMTP_SSL(smtp_server)
企业邮箱报错
搜索后,我们很快就会发现,解决方案是:在登录(login )之前调用**starttls()**方法就可以了。也就是在代码中加入这样一行:
这些问题基本上都能通过搜索解决。如果你搞不清楚是什么问题的话,试一试将端口参数改一下,使用默认端口25。
1 2 3 4 5 6 7 server = smtplib.SMTP_SSL() server.connect(smtp_server,465 ) server = smtplib.SMTP() server.connect(smtp_server,25 )
3.2、版本2.0:给自己发一封完整邮件 1、丰富邮件头 邮件头(header,没错它也叫header)是这一块区域,包括主题、发件人、收件人等信息:
1 2 3 4 5 from email.header import Headermsg['From' ] = Header('xxx' ) msg['To' ] = Header('xxx' ) msg['Subject' ] = Header('xxx' )
第一行代码,从email包引入Header()方法 。**Header()**是用来构建邮件头的。
标准邮件需要三个头部信息:From , To 和 Subject ,第三到五行代码就提供了这三个信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import smtplibfrom email.mime.text import MIMETextfrom email.header import Headerfrom_addr = 'xxx@qq.com' password = '你的授权码数字' to_addr = 'xxx@qq.com' smtp_server = 'smtp.qq.com' msg = MIMEText('send by python' ,'plain' ,'utf-8' ) msg['From' ] = Header('吴枫' ) msg['To' ] = Header('小可爱' ) msg['Subject' ] = Header('来自吴枫的问候' ) server = smtplib.SMTP_SSL() server.connect(smtp_server,465 ) server.login(from_addr, password) server.sendmail(from_addr, to_addr, msg.as_string()) server.quit()
2、丰富正文内容 1 2 3 4 5 6 7 text = '''亲爱的学员,你好! 我是吴枫老师,能遇见你很开心。 希望学习Python对你不是一件困难的事情! 人生苦短,我用Python ''' msg = MIMEText(text,'plain' ,'utf-8' )
合并
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import smtplibfrom email.mime.text import MIMETextfrom email.header import Headerfrom_addr = 'xxx@qq.com' password = '你的授权码数字' to_addr = 'xxx@qq.com' smtp_server = 'smtp.qq.com' text = '''亲爱的学员,你好! 我是吴枫老师,能遇见你很开心。 希望学习Python对你不是一件困难的事情! 人生苦短,我用Python ''' msg = MIMEText(text,'plain' ,'utf-8' ) msg['From' ] = Header(from_addr) msg['To' ] = Header(to_addr) msg['Subject' ] = Header('python test' ) server = smtplib.SMTP_SSL() server.connect(smtp_server,465 ) server.login(from_addr, password) server.sendmail(from_addr, to_addr, msg.as_string()) server.quit()
之前也提到了,出于保护隐私的目的,我们可以把收发件人,和授权码这些信息用**input()**变成需要输入的模式。
1 2 3 4 5 6 from_addr = input ('请输入登录邮箱:' ) password = input ('请输入邮箱授权码:' ) to_addr = input ('请输入收件邮箱:' )
3.3、版本3.0:群发完整邮件
一种、 一,是将收件人信箱的变量设置成一个可以装多个内容的列表:
1 to_addrs = ['wufeng@qq.com' ,'kaxi@qq.com' ]
需要注意的是,to_addrs 变量也将作为参数被传入Header 方法中:
1 msg['To' ] = Header(to_addrs)
直接运行程序的话,这里就会发生错误:AttributeError: ‘list’ object has no attribute ‘decode’。
如果你有查看官方文档的好习惯,那么你会发现这是因为Header 接受的第一个参数的数据类型必须要是字符串或者字节,列表不能解码。
也就是说,我们要将to_addrs 变成一个字符串,怎么做呢?好像没有学过?其实,我们只需要对这行代码做一个这样的操作:
1 msg['to' ] = Header("," .join(to_addrs))
**join()的用法是 str.join(sequence)**,str代表在这些字符串之中你要用什么字符串来连接,你可以用逗号,空格,下划线等等。要将列表的元素合并,当然我们就直接使用逗号来连接了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import smtplibfrom email.mime.text import MIMETextfrom email.header import Headerfrom_addr = 'xxx@qq.com' password = '你的授权码数字' to_addrs = ['wufeng@qq.com' ,'kaxi@qq.com' ] smtp_server = 'smtp.qq.com' text='''亲爱的学员,你好! 我是吴枫老师,能遇见你很开心。 希望学习Python对你不是一件困难的事情! 人生苦短,我用Python ''' msg = MIMEText(text,'plain' ,'utf-8' ) msg['From' ] = Header(from_addr) msg['To' ] = Header("," .join(to_addrs)) msg['Subject' ] = Header('python test' ) server = smtplib.SMTP_SSL() server.connect(smtp_server,465 ) server.login(from_addr, password) server.sendmail(from_addr, to_addrs, msg.as_string()) server.quit()
这里有个小细节需要注意:我们将收件人变量名从to_addr 改成了复数to_addrs 之后,后面用到这个变量的地方,也要进行修改!
二种、 第二种方法是采用询问“是否继续输入邮箱地址”的方式,并用while循环来实现多个收件人的功能。
由于我们要存储输入的内容,供发邮件的时候使用。所以需要定义一个空列表to_addrs ,用来存放收件人邮箱地址。输入邮箱地址的时候,地址会被追加写进列表。
因为循环次数不固定,所以我们选择while循环来做。我的这段代码是这样的,加了一个print()函数来确认结果:
1 2 3 4 5 6 7 8 9 10 11 12 to_addrs = [] while True : a=input ('请输入收件人邮箱:' ) to_addrs.append(a) b=input ('是否继续输入,n退出,任意键继续:' ) if b == 'n' : break print (to_addrs)
合并
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import smtplibfrom email.mime.text import MIMETextfrom email.header import Headerfrom_addr = input ('请输入登录邮箱:' ) password = input ('请输入邮箱授权码:' ) to_addrs = [] while True : a=input ('请输入收件人邮箱:' ) to_addrs.append(a) b=input ('是否继续输入,n退出,任意键继续:' ) if b == 'n' : break smtp_server = 'smtp.qq.com' text='''亲爱的学员,你好! 我是吴枫老师,能遇见你很开心。 希望学习Python对你不是一件困难的事情! 人生苦短,我用Python ''' msg = MIMEText(text,'plain' ,'utf-8' ) msg['From' ] = Header(from_addr) msg['To' ] = Header("," .join(to_addrs)) msg['Subject' ] = Header('python test' ) server = smtplib.SMTP_SSL(smtp_server) server.connect(smtp_server,465 ) server.login(from_addr, password) server.sendmail(from_addr, to_addrs, msg.as_string()) server.quit()
三种、 将邮箱地址写入csv模块的方法是**write()**,步骤是:1.引入csv模块;2.提供需要写入csv文件的数据,3.建文件并写入。
1 2 3 4 5 6 7 8 9 10 import csvdata = [['wufeng ' , 'wufeng@qq.com' ],['kaxi' , 'kaxi@qq.com' ]] with open ('to_addrs.csv' , 'w' , newline='' ) as f: writer = csv.writer(f) for row in data: writer.writerow(row)
但是我们没有这样的文件,所以还需要新建一个to_addrs.csv 文件。我们使用的是with语句新建文件,这样做的好处是:到达语句末尾时,会自动关闭文件,不需要close()。
紧接着,我们定义了一个变量writer进行写入,将刚才的文件变量传进来。
之后就是进行数据写入,写入的方法是writerow()。通过遍历列表data将数据一行行写到了 to_addrs.csv 文件中。
读取的过程就异曲同工了。利用的是**read()**方法。步骤是:1.引入csv模块;2.打开csv文件;3.读取需要的数据。
1 2 3 4 5 6 7 import csvwith open ('to_addrs.csv' , 'r' ) as f: reader = csv.reader(f) for row in reader: to_addrs=row[1 ]
row[1]表示csv文件中第1列的数据。想一想:wufeng和kaxi属于第0列的数据,邮箱地址则属于第1列的数据,所以第1列数据才是我们需要的!
好啦,接下来要做的就是把取出来的内容赋值给变量to_addrs,并在发送邮件时使用。先提个醒,注意哪些代码需要在for循环内部缩进。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import smtplibfrom email.mime.text import MIMETextfrom email.header import Headerimport csvfrom_addr = input ('请输入登录邮箱:' ) password = input ('请输入邮箱授权码:' ) smtp_server = 'smtp.qq.com' text='''亲爱的学员,你好! 我是吴枫老师,能遇见你很开心。 希望学习python对你不是一件困难的事情! 人生苦短,我用Python ''' data = [['wufeng ' , 'wufeng@qq.com' ],['kaxi' , 'kaxi@qq.com' ]] with open ('to_addrs.csv' , 'w' , newline='' ) as f: writer = csv.writer(f) for row in data: writer.writerow(row) with open ('to_addrs.csv' , 'r' ) as f: reader = csv.reader(f) for row in reader: to_addrs=row[1 ] msg = MIMEText(text,'plain' ,'utf-8' ) msg['From' ] = Header(from_addr) msg['To' ] = Header(to_addrs) msg['Subject' ] = Header('python test' ) server = smtplib.SMTP_SSL() server.connect(smtp_server,465 ) server.login(from_addr, password) server.sendmail(from_addr, to_addrs, msg.as_string()) server.quit()
此外,你还可以为这个程序加一段异常处理代码,也就是**try…except…**语句来帮助你更好地处理你遇到的问题。
1 2 3 4 5 try : server.sendmail(from_addr, to_addrs, msg.as_string()) print ('恭喜,发送成功' ) except : print ('发送失败,请重试' )
第18关 编程思维:产品思维 1、流程图 工欲善其事必先利其器,我们首先要学习的是“流程图”,如果不先掌握“流程图”这个分析与思考的工具,就很难实践“产品设计”的相关方法。
相信大家之前一定也接触过流程图,我们可以把流程图理解成“用一种图示描述事物进行的过程”。比如我们去注册使用共享单车的过程,可以画出这样的流程图:
掌握了流程图后,你既可以用它分析思考问题,也可以用它搭建产品框架,还能用它设计代码逻辑。
所有的流程图,总结起来有三种类型:
1.1、顺序结构 当一件事情是按顺序进行的时候,我们就用顺序结构。一般会用到三种图形:
有些我们习以为常的行为,也可以拆解成一定的步骤。比如当我们在淘宝剁手的时候,粗糙的流程图是长这样的:
现在请你来思考一下,对于“煮饭”这件事,一个简单的流程图可以怎么画?
流程图画出来之后,可以帮助我们梳理代码逻辑,逐步实现。
比如我们想写一个根据圆的半径(R)来求面积(S)和周长(L)的代码,可以画出以下的流程图:
1 2 3 4 5 6 7 8 9 pi = 3.14 print ('欢迎使用圆的面积和周长计算程序。' )R = float (input ('请输入圆的半径:' )) S = pi*R*R L = 2 *pi*R print ('圆的面积是:' + str (S) + '\n' + '圆的周长是:' + str (L))
1.2、条件结构
“条件结构”主要是为了展现,在不同的条件下如何按不同的逻辑行事。
在这里,我们要补充一个图形,当流程图中遇到需要判断条件的节点时,需要用“菱形”表示。
例如你想写一个【求绝对值】的程序,将正数负数都转化为正数。
1 2 3 4 5 6 7 print ('欢迎使用绝对值计算程序。' )R = float (input ('请输入数字:' )) if R>=0 : S = R elif R<0 : S = -R print ('所求绝对值是:' + str (S))
1.3、循环结构
在前面“共享单车”的流程图案例中,就有一个循环结构:
以淘宝购物为例,在最后提交订单的时候,也有一个循环结构:
第二个循环结构比第一个多了一处菱形,用来负责“条件判断”,当条件为“不成功”时则继续循环。
摩拜单车使用逻辑:
先要注册、交押金并充值
找到摩拜单车,用手机扫码解锁单车,然后开始计费
有时候车是坏的,手机会提示:“此车需要维修,请换一辆车”,这种情况不会进入计费,需要换一辆车再扫码
到目的地后锁车,可以选择余额支付、微信支付、支付宝支付
支付的时候如果余额不足会失败,需要更换其他支付方式。
总结:
2、产品设计
2.1、如何提需求 要想提出需求,我们首先要学会留意生活和工作中,哪些地方不方便、不爽、存在障碍,也就是我们常说的“痛点”。
根据大家现在的技能水平,有两种需求最值得关注:
我们在平时的工作和生活中都可以尝试思考,是否有“重复性劳动”可以被程序替代?是否能够“制作工具”帮我们解决问题?
另一类需求来源是“制作工具解决问题”。有时候,我们可以通过技术手段制作一些实用的工具,提升效率。
的确,许多需求完成起来还比较困难。但你应该先记录下来,即使是你现在一时间还无法解决的需求。
记录需求的好处是“建立明确的编程目标”。以实现这些需求为目标,你可以很清晰地感受到自己编程能力的成长,有朝一日你实现自己需求,制作出完整产品的时候,一定会开心得像个两百斤的孩子。
这里,我推荐大家用一张表格做记录:
2.2、如何设计解决方案 提完需求的下一步,就是设计解决方案。也就是说,我们要设计编程思路,解决之前提出的需求。
设计编程思路解决需求,其实和“求解编程问题”类似。还记得我们之前的求解编程问题的5个步骤吗?
“为需求设计解决方案”其实就是另一种形式的“解编程题”,它们都需要明确目标、思考需要用到的知识、思考切入点、尝试一步步解决。
第0关我给大家讲过一个小案例:我们公司的行政小姐姐,每个月都需要统计考勤,计算大家的迟到时长和迟到次数。但是这件事枯燥无味,显然是一个重复性劳动。
拿到这个需求,我们就可以制作第一张流程图,拆解、分析这项重复性工作是如何进行的:
在这里,使用流程图分析,可以让自己清晰地看到整个工作过程。这有助于我们接下来思考问题:哪些工作可以被程序替代?
我们知道,程序可以很容易地读写文件、处理信息(比如做计算),所以,在这个案例中,标黄的都可以比较方便地利用程序完成:
我们知道了要用程序去替代这些繁琐的步骤,接下来的任务就是【写出代码逻辑】。
首先我们可以优化一下流程图。比如标记颜色是为了方便人完成工作,机器并不需要这个步骤,用字典存储数据即可。
制作出“改良版流程图”后,我们就可以开始下一步:求解编程问题的5个步骤。
尝试实现代码的过程,是对我们已学知识的检验。但无可避免地会遇到一些卡点:
那么,用流程图总结一下刚刚我们谈论的这些内容,就可以得出产品设计的步骤了:
第19关 项目实操:毕业项目 1、明确项目目标 房源信息
2、分析过程,拆解项目 希望把一个小区某一栋楼内的所有户室的资料录入到excel表里,这栋楼的资料是这样子的:
流程图:
可见,这里的关键点是找到数据中的规律,确定可以复用的模版数据,我们在模块那关也学到csv模块是可以处理excel文件格式的,所以老师将这一项目拆解成3个版本,也可以当成是三大步骤。
3、逐步执行,代码实现 3.1、版本1.0: 输入表头,确定模版数据 当我们要在Python读写excel的时候,调用csv模块是个很好的选择。
1 2 3 4 5 6 7 8 9 import csvwith open ('assets.csv' , 'a' , newline='' ) as csvfile: writer = csv.writer(csvfile, dialect='excel' ) header=['小区名称' , '地址' , '建筑年份' , '楼栋' , '单元' , '户室' , '朝向' , '面积' ] writer.writerow(header)
确定好表头之后,接下来,我们要确定以哪些数据为模版数据,也就是哪些数据只需输入一次便可重复利用,写入循环。
我们一个个来看,一个小区一栋楼的小区名称、地址、建筑年份、肯定是相同的,所以可以输入一次,复用所有。
title = input(‘请输入小区名称’)
而同一栋内部的单元分布也许是不同的,比如说有的单元只有两户室,有的单元有四户室,所以它的房间朝向、面积也会不同,所以一个单元的数据不能做模板数据。
我们再缩小范围,我们会发现在同一单元下,每一楼的户型和朝向一般是一样的,也就是只需要知道一个单元下某一楼层的数据,该单元的其它楼层都可以复用,区别只是户室号。
确定了以此为模版数据,下一阶段我们就来看看具体怎么转化成代码的形式。
3.2、阶段2:获取、复用模版数据 在阶段1,我们已经确定了模版数据是一个单元下某一层楼的数据,也就是说我们只要拿到起始楼层的每个户室的数据(朝向和面积),这个单元内其他楼层的户室都可以套用。
而户室号一般是由楼层+后两位序号(以下我会简称为尾号)组成的,如201,202,203,204;301,302,303,304…尾号是统一的,变的只是前面的楼层数(每层加一),所以户室号拆成两部分处理会方便我们后续的操作。
那么,接下来,我们就来获取模版数据吧~不过每次获取数据前我们就得想好我们要用什么样的形式存储数据。
现在我们需要拿到的是起始楼层每一个户室的朝向和面积,我们可以判断出朝向和面积是并列关系,它是从属于户室的。
我们很自然能想到这里用字典嵌套列表的形式会更方便,其中字典的键是户室号,面积和朝向组成的列表为字典的值,类似这种形式。
1 2 start_floor_rooms = {301 :['南北' ,70 ],302 :['南北' ,70 ],303 :['东西' ,80 ],304 :['东西' ,80 ]}
我们一步步来看,首先我们来把第一对键值对 301:['南北',70] 放进字典start_floor_rooms里,这是我们之前反复接触过的,你可以先看代码和注释。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 start_floor = input ('请输入起始楼层:' ) end_floor = input ('请输入终止楼层:' ) start_floor_rooms = {} floor_last_number = [] last_number = input ('请输入起始楼层户室的尾号:(如01,02)' ) floor_last_number.append(last_number) room_number = int (start_floor + last_number) direction = int (input ('请输入 %d 的朝向(南北朝向输入1,东西朝向输入2):' % room_number )) area = int (input ('请输入 %d 的面积,单位 ㎡ :' % room_number)) start_floor_rooms[room_number] = [direction,area] print (start_floor_rooms)
可见,这段代码只能让我们获取起始楼层一个户室的信息,为了获取起始楼层其他户室的信息,我们需要加入循环。
因为每一单元的户室数不是固定的,所以用while循环会更妥当,我们可以先定义一个循环控制量,让循环条件为True,再“人为”地打破循环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 start_floor = input ('请输入起始楼层:' ) end_floor = input ('请输入终止楼层:' ) input ('接下来请依次输入起始层每个房间的户室尾号、南北朝向及面积,按任意键继续' )start_floor_rooms = {} floor_last_number = [] room_loop = True while room_loop: last_number = input ('请输入起始楼层户室的尾号:(如01,02)' ) floor_last_number.append(last_number) room_number = int (start_floor + last_number) direction = int (input ('请输入 %d 的朝向(南北朝向输入1,东西朝向输入2):' % room_number )) area = int (input ('请输入 %d 的面积,单位 ㎡ :' % room_number)) start_floor_rooms[room_number] = [direction,area] continued= input ('是否需要输入下一个尾号?按 n 停止输入,按其他任意键继续:' ) if continued == 'n' : room_loop = False else : room_loop = True print (start_floor_rooms)
好的,现在我们就已经获得了起始楼层所有户室的数据,下一步我们就要将这层的数据迁移到其他楼层里,即只需把户室号的楼层数加一。
那怎么迁移呢?我们的第一反应可能是给每一个楼层都创建一个新字典,这样虽然可行,但随着楼层的增加,字典就会有非常多个,不好管理,
所以把一个单元内所有楼层的数据放在一块会更方便我们的处理,也就是说将每一个楼层的字典统一放在一个存放单元级的字典里,我们希望的格式应该是这样的:
1 2 3 4 5 6 7 8 9 10 11 12 star_floor = 3 end_floor = 5 start_floor_rooms = {301 :[1 ,80 ],302 :[1 ,80 ],303 :[2 ,90 ],304 :[2 ,90 ]} unit_rooms={ 3 :{301 :[1 ,80 ],302 :[1 ,80 ],303 :[2 ,90 ],304 :[2 ,90 ]}, 4 :{401 :[1 ,80 ],402 :[1 ,80 ],403 :[2 ,90 ],404 :[2 ,90 ]}, 5 :{501 :[1 ,80 ],502 :[1 ,80 ],503 :[2 ,90 ],504 :[2 ,90 ]} }
虽然unit_rooms这个结构看起来很复杂,但我们分析一下就知道,这是字典嵌套字典的情况。(为了方便讲解,以下我会把最外层的字典称为大字典,里层的字典称为小字典)
大字典的键是楼层数,值是小字典,而每个小字典和初始楼层start_floor_rooms的数据只是户室号的区别。
那么接下来我们只需往unit_rooms不断添加键值对就可以了。为了化繁为简,展示重点,接下来我会给出一些固定变量,是我们上一阶段的代码能获取的结果。
1 2 3 4 5 6 7 8 start_floor = '3' start_floor_rooms = {301 :[1 ,80 ],302 :[1 ,80 ],303 :[2 ,90 ]} unit_rooms = {} unit_rooms[int (start_floor)] = start_floor_rooms print (unit_rooms)
现在字典里已经有了3楼所有户室的信息,接下来就是往字典里添加其他楼层的信息(键值对)。
假设现在的单元只有3楼和4楼,每一楼层都有3个户室,我们来看看怎么把3楼的数据复制给4楼,并放在unit_rooms里。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 start_floor = '3' end_floor = '4' floor_last_number = ['01' ,'02' ,'03' ] start_floor_rooms = {301 :[1 ,80 ], 302 :[1 ,80 ], 303 :[2 ,90 ]} unit_rooms = {} unit_rooms[int (start_floor)] = start_floor_rooms floor_rooms = {} for i in range (len (start_floor_rooms)): number = '4' + floor_last_number[i] info = start_floor_rooms[int (start_floor + floor_last_number[i])] floor_rooms[int (number)] = info unit_rooms[4 ] = floor_rooms print (unit_rooms)
在一开始,我们可以通过input()询问知道一栋楼里有多少层。
1 2 start_floor = input ('请输入起始楼层:' ) end_floor = input ('请输入终止楼层:' )
现在我们假设一栋楼是3-7楼,即start_floor = 3,end_floor = 7。
因为楼层是已知的,那么这里用for循环会更方便一些,循环的执行次数应该是除初始楼层之外剩余的楼层数。(因为初始楼层是模版数据,需要手动录入)
也就是说如果是3-7楼,我们的循环是执行4、5、6、7四次,所以循环的条件就可以写成:
1 2 for floor in range (start_floor + 1 , end_floor + 1 ):
那么,我们将循环加入上一步,结果就是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 start_floor = '3' end_floor = '7' floor_last_number = ['01' ,'02' ,'03' ] start_floor_rooms = {301 :[1 ,80 ],302 :[1 ,80 ],303 :[2 ,90 ]} unit_rooms = {} unit_rooms[int (start_floor)] = start_floor_rooms for floor in range (int (start_floor) + 1 , int (end_floor) + 1 ): floor_rooms = {} for i in range (len (start_floor_rooms)): number = str (floor) + floor_last_number[i] info = start_floor_rooms[int (start_floor + floor_last_number[i])] floor_rooms[int (number)] = info unit_rooms[floor] = floor_rooms print (unit_rooms)
很好,现在我们就把一个单元里所有楼层的数据放进了字典unit_rooms里了,接下来就是写入我们在一开始创建好的csv文件里。
3.3、阶段3.0:写入csv文件 在阶段2.0,我们把一个单元内所有户室的数据都存在unit_rooms这个字典里,理论上我们已经可以以单元为单位写入到csv文件,现在最关键的是如何从字典取出我们想要的数据。
我们来看一开始已经输入过的表头,它们是’小区名称’, ‘地址’, ‘建筑年份’, ‘楼栋’, ‘单元’, ‘户室’, ‘朝向’, ‘面积’
其中’小区名称’,’地址’,’建筑年份’, ‘楼栋’, ‘单元’都需要手动输入,并赋值给相应的变量,不过只需输入一遍就能复用到其余所有单元格里。
1 2 3 4 5 title = input ('请输入小区名称' ) address = input ('请输入小区地址:' ) year = input ('请输入小区建造年份:' ) block = input ('请输入楼栋号:' ) unit = input ('请输入单元号:' )
剩下的’户室’、’朝向’和’面积‘都存储在字典unit_rooms里,假设现在字典是长这样的:
1 2 3 4 unit_rooms={ 3 :{301 :[1 ,80 ],302 :[1 ,80 ],303 :[2 ,90 ],304 :[2 ,90 ]}, 4 :{401 :[1 ,80 ],402 :[1 ,80 ],403 :[2 ,90 ],404 :[2 ,90 ]}, 5 :{501 :[1 ,80 ],502 :[1 ,80 ],503 :[2 ,90 ],504 :[2 ,90 ]} }
我们来思考一下要怎么一次性把户室号(301-304,401-404,501-504)和户室号对应的朝向和面积都一次性取出来呢?
同样我们把最外层的字典unit_rooms成为大字典,里面嵌套的字典成为小字典(sub_dict)。
可见,大字典的值是小字典(sub_dict),其中户室是小字典的键,朝向是小字典的值(列表)的第0个元素,面积是小字典的值(列表)的第1个元素。
也就是说我们需要的数据都在大字典的值里,所以第一步我们需要遍历大字典里的键(key),来取出值(value)。
这当然没问题,不过老师在这里想给大家介绍一种新方法,可以直接遍历字典里所有的值,这样就不用去数字典里有多少个键值对了。它的语法是:
1 2 3 4 for value in DictName.values():
所以,如果我们要取出unit_rooms的值,就可以写成:
1 2 3 4 5 6 unit_rooms = {3 :{301 :[1 ,80 ],302 :[1 ,80 ],303 :[2 ,90 ],304 :[2 ,90 ]}, 4 :{401 :[1 ,80 ],402 :[1 ,80 ],403 :[2 ,90 ],404 :[2 ,90 ]}, 5 :{501 :[1 ,80 ],502 :[1 ,80 ],503 :[2 ,90 ],504 :[2 ,90 ]} } for sub_dict in unit_rooms.values(): print (sub_dict)
好,现在我们已经取出小字典(sub_dict)了,前面我们分析过户室号是sub_dict的键,朝向和面积是sub_dict的值,所以下一步就是要遍历sub_dict的键和值,这里老师也介绍一种新的语法。
1 2 3 for k,v in DictName.items():
打印出字典下每一户室的门牌号、朝向和面积,格式为:【户室号:301 朝向:1 面积:80 】
1 2 3 4 5 6 7 8 9 unit_rooms = {3 :{301 :[1 ,80 ],302 :[1 ,80 ],303 :[2 ,90 ],304 :[2 ,90 ]}, 4 :{401 :[1 ,80 ],402 :[1 ,80 ],403 :[2 ,90 ],404 :[2 ,90 ]}, 5 :{501 :[1 ,80 ],502 :[1 ,80 ],503 :[2 ,90 ],504 :[2 ,90 ]} } for sub_dict in unit_rooms.values(): for room,info in sub_dict.items(): print ('户室号:%d 朝向 %d 面积:%d' % (room,info[0 ],info[1 ]))
现在还有个细节是一开始我们将’南北’记成1,’东西’记成2,所以现在我们需要改回来,当然你可以写入csv文件再全部替换,不过我们还是有始有终,在Python完成操作吧。
事实上我们用条件判断和赋值语句就可以了。
1 2 3 4 5 6 7 8 9 10 unit_rooms = {3 :{301 :[1 ,80 ],302 :[1 ,80 ],303 :[2 ,90 ],304 :[2 ,90 ]}, 4 :{401 :[1 ,80 ],402 :[1 ,80 ],403 :[2 ,90 ],404 :[2 ,90 ]}, 5 :{501 :[1 ,80 ],502 :[1 ,80 ],503 :[2 ,90 ],504 :[2 ,90 ]} } for sub_dict in unit_rooms.values(): for room,info in sub_dict.items(): if info[0 ] == 1 : info[0 ] = '南北' elif info[0 ] == 2 : info[0 ] = '东西'
在这里,我也介绍另外一种方法,是对列表索引的活用,留意第7行和第9行的代码。
1 2 3 4 5 6 7 8 9 unit_rooms = {3 :{301 :[1 ,80 ],302 :[1 ,80 ],303 :[2 ,90 ],304 :[2 ,90 ]}, 4 :{401 :[1 ,80 ],402 :[1 ,80 ],403 :[2 ,90 ],404 :[2 ,90 ]}, 5 :{501 :[1 ,80 ],502 :[1 ,80 ],503 :[2 ,90 ],504 :[2 ,90 ]} } for sub_dict in unit_rooms.values(): for room,info in sub_dict.items(): dire = ['' , '南北' , '东西' ] print (dire[info[0 ]])
最后一行:因为info[0]的值不是1就是2,所以dire[info[0]]不是dire[1]就是dire[2]。
如果是dire[1],就是取列表dire的第一个元素’南北’,dire[2]则取’东西’。所以代码就是:
1 2 3 4 5 6 7 8 unit_rooms = {3 :{301 :[1 ,80 ],302 :[1 ,80 ],303 :[2 ,90 ],304 :[2 ,90 ]}, 4 :{401 :[1 ,80 ],402 :[1 ,80 ],403 :[2 ,90 ],404 :[2 ,90 ]}, 5 :{501 :[1 ,80 ],502 :[1 ,80 ],503 :[2 ,90 ],504 :[2 ,90 ]} } for sub_dict in unit_rooms.values(): for room,info in sub_dict.items(): dire = ['' , '南北' , '东西' ] print ('户室号:%d 朝向:%s 面积:%d' % (room,dire[info[0 ]],info[1 ]))
那么,截至目前,我们似乎把一切准备工作都做完了,我们来把前面的代码都整合在一起:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 import csvwith open ('assets.csv' , 'a' , newline='' ) as csvfile: writer = csv.writer(csvfile, dialect='excel' ) header=['小区名称' , '地址' , '建筑年份' , '楼栋' , '单元' , '户室' , '朝向' , '面积' ] writer.writerow(header) title=input ('请输入小区名称:' ) address = input ('请输入小区地址:' ) year = input ('请输入小区建造年份:' ) block = input ('请输入楼栋号:' ) unit=input ('请输入单元号:' ) start_floor = input ('请输入起始楼层:' ) end_floor = input ('请输入终止楼层:' ) input ('接下来请输入起始层每个房间的门牌号、南北朝向及面积,按任意键继续' )start_floor_rooms = {} floor_last_number = [] room_loop = True while room_loop: last_number = input ('请输入起始楼层户室的尾号:(如01,02)' ) floor_last_number.append(last_number) room_number = int (start_floor + last_number) direction = int (input ('请输入 %d 的朝向(南北朝向输入1,东西朝向输入2):' % room_number )) area = int (input ('请输入 %d 的面积,单位 ㎡ :' % room_number)) start_floor_rooms[room_number] = [direction,area] continued= input ('是否需要输入下一个尾号?按 n 停止输入,按其他任意键继续:' ) if continued == 'n' : room_loop = False else : room_loop = True unit_rooms = {} unit_rooms[start_floor] = start_floor_rooms for floor in range (int (start_floor) + 1 , int (end_floor) + 1 ): floor_rooms = {} for i in range (len (start_floor_rooms)): number = str (floor) + floor_last_number[i] info = start_floor_rooms[int (start_floor + floor_last_number[i])] floor_rooms[int (number)] = info unit_rooms[floor] = floor_rooms with open ('assets.csv' , 'a' , newline='' )as csvfile: writer = csv.writer(csvfile, dialect='excel' ) for sub_dict in unit_rooms.values(): for room,info in sub_dict.items(): dire = ['' , '南北' , '东西' ] writer.writerow([title,address,year,block,unit,room,dire[info[0 ]],info[1 ]])
截至目前,我们只是完成了一个单元内所有户室的循环,考虑到一栋楼里可能会有多个单元,所以我们要在一开始再加入一层单元间的循环。我们的最后代码就变成这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 import csvwith open ('assets.csv' , 'a' , newline='' ) as csvfile: writer = csv.writer(csvfile, dialect='excel' ) header=['小区名称' , '地址' , '建筑年份' , '楼栋' , '单元' , '户室' , '朝向' , '面积' ] writer.writerow(header) title=input ('请输入小区名称:' ) address = input ('请输入小区地址:' ) year = input ('请输入小区建造年份:' ) block = input ('请输入楼栋号:' ) unit_loop = True while unit_loop: unit=input ('请输入单元号:' ) start_floor = input ('请输入起始楼层:' ) end_floor = input ('请输入终止楼层:' ) input ('接下来请输入起始层每个房间的门牌号、南北朝向及面积,按任意键继续' ) start_floor_rooms = {} floor_last_number = [] room_loop = True while room_loop: last_number = input ('请输入起始楼层户室的尾号:(如01,02)' ) floor_last_number.append(last_number) room_number = int (start_floor + last_number) direction = int (input ('请输入 %d 的朝向(南北朝向输入1,东西朝向输入2):' % room_number )) area = int (input ('请输入 %d 的面积,单位 ㎡ :' % room_number)) start_floor_rooms[room_number] = [direction,area] continued= input ('是否需要输入下一个尾号?按 n 停止输入,按其他任意键继续:' ) if continued == 'n' : room_loop = False else : room_loop = True unit_rooms = {} unit_rooms[start_floor] = start_floor_rooms for floor in range (int (start_floor) + 1 , int (end_floor) + 1 ): floor_rooms = {} for i in range (len (start_floor_rooms)): number = str (floor) + floor_last_number[i] info = start_floor_rooms[int (start_floor + floor_last_number[i])] floor_rooms[int (number)] = info unit_rooms[floor] = floor_rooms with open ('assets.csv' , 'a' , newline='' )as csvfile: writer = csv.writer(csvfile, dialect='excel' ) for sub_dict in unit_rooms.values(): for room,info in sub_dict.items(): dire = ['' , '南北' , '东西' ] writer.writerow([title,address,year,block,unit,room,dire[info[0 ]],info[1 ]]) unit_continue = input ('是否需要输入下一个单元?按 n 停止单元输入,按其他任意键继续:' ) if unit_continue == 'n' : unit_loop = False else : unit_loop = True print ('恭喜你,资产录入工作完成!' )




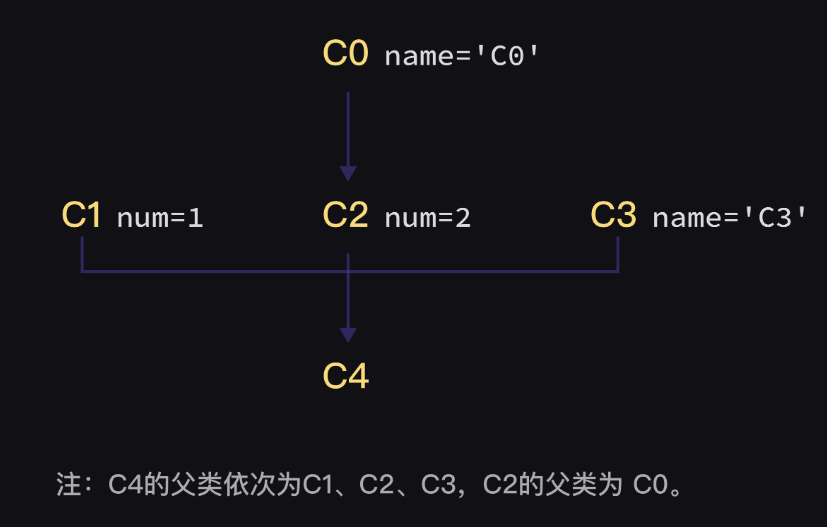


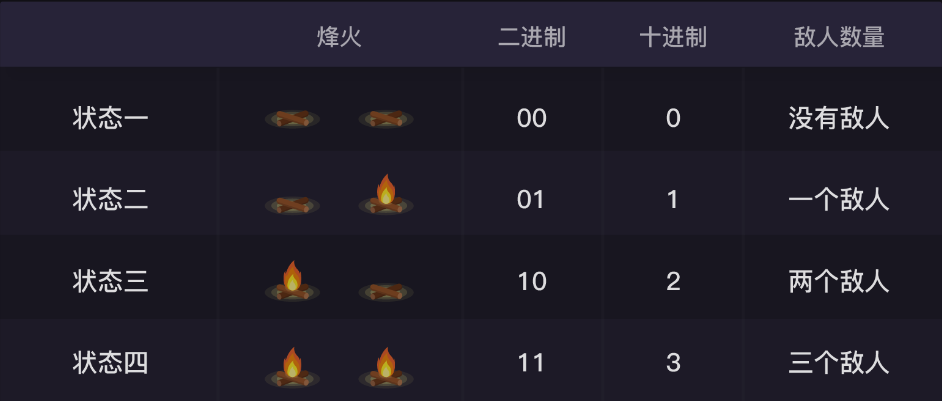




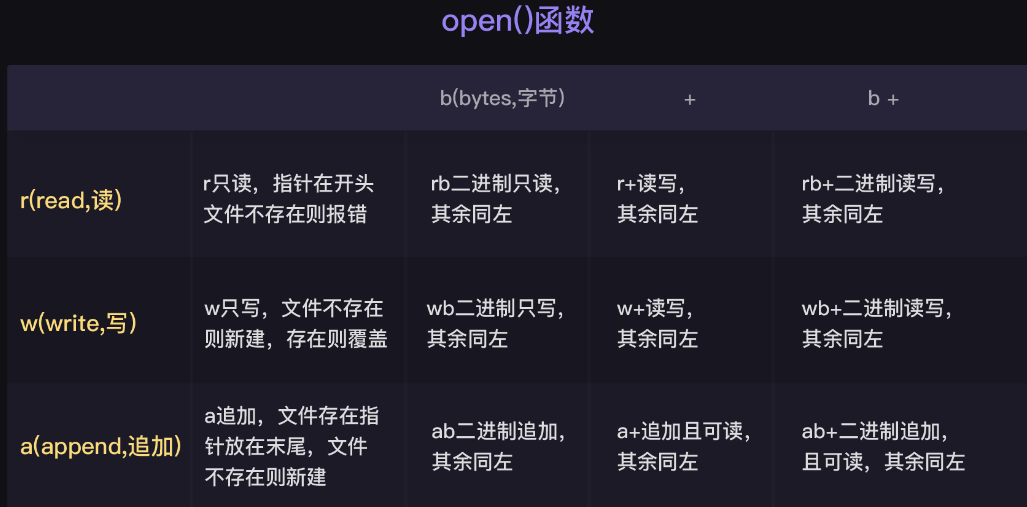
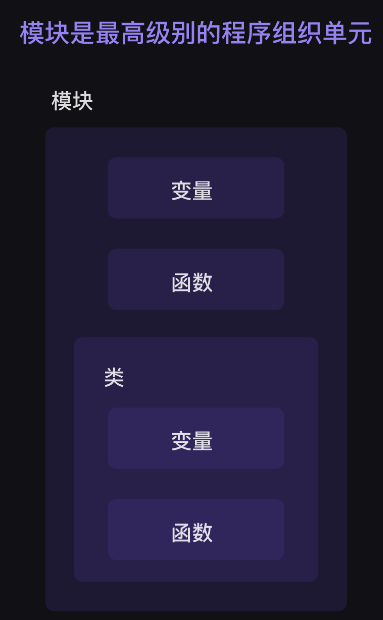


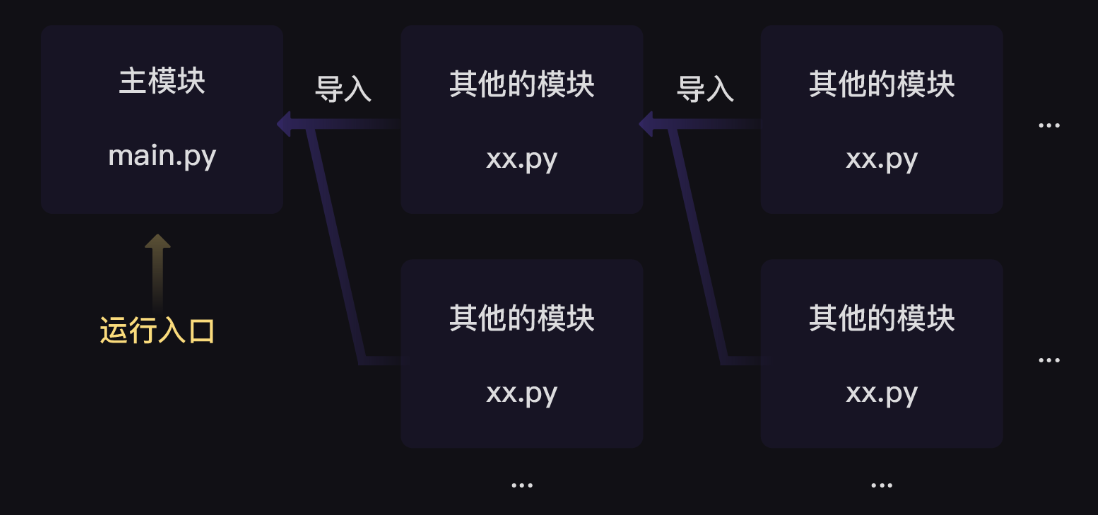



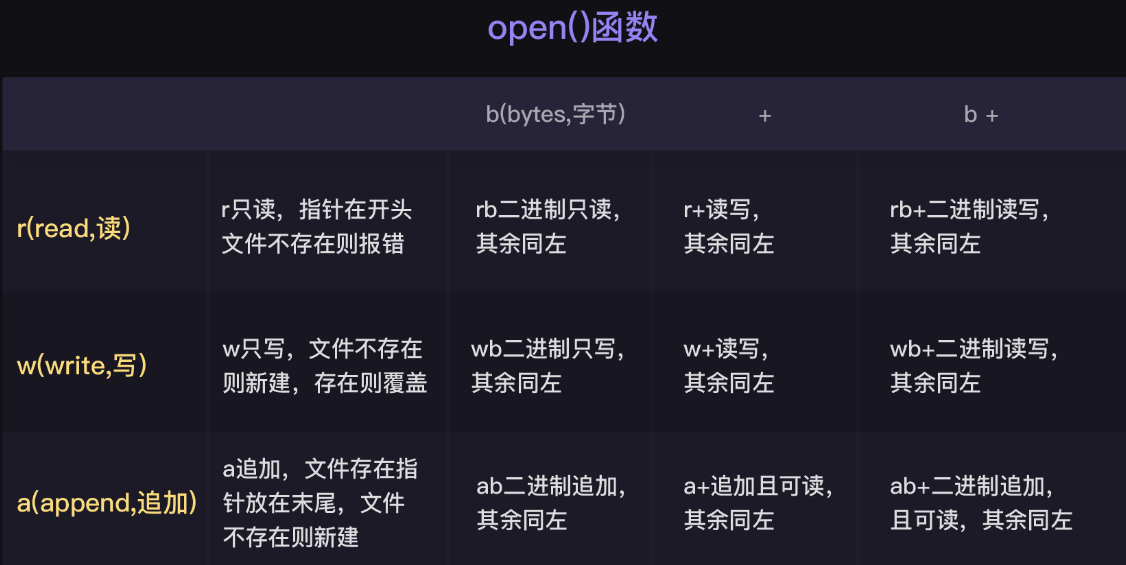





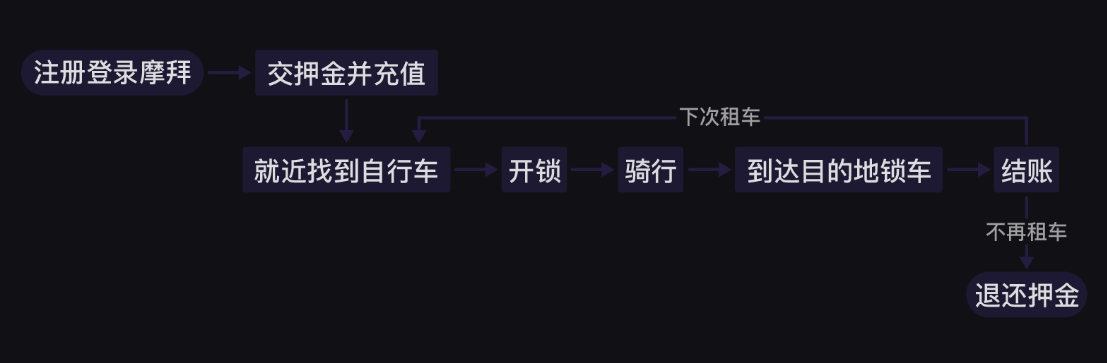
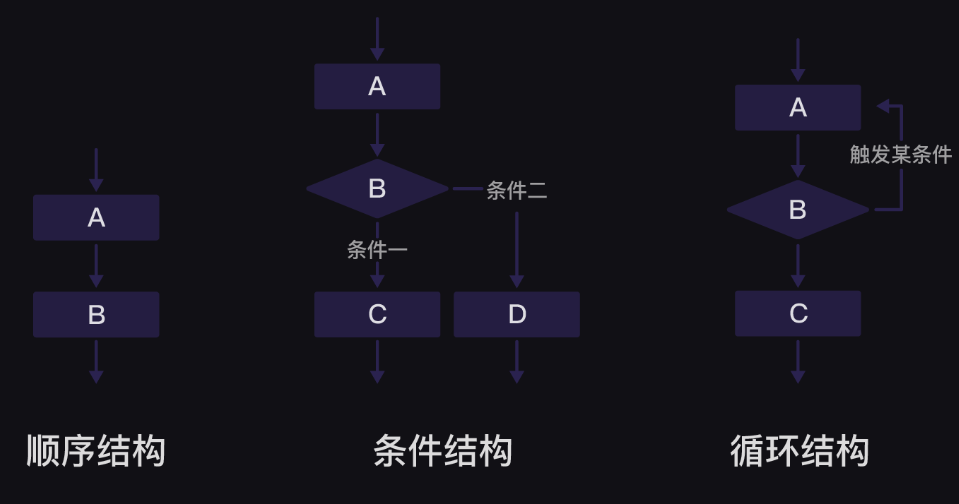
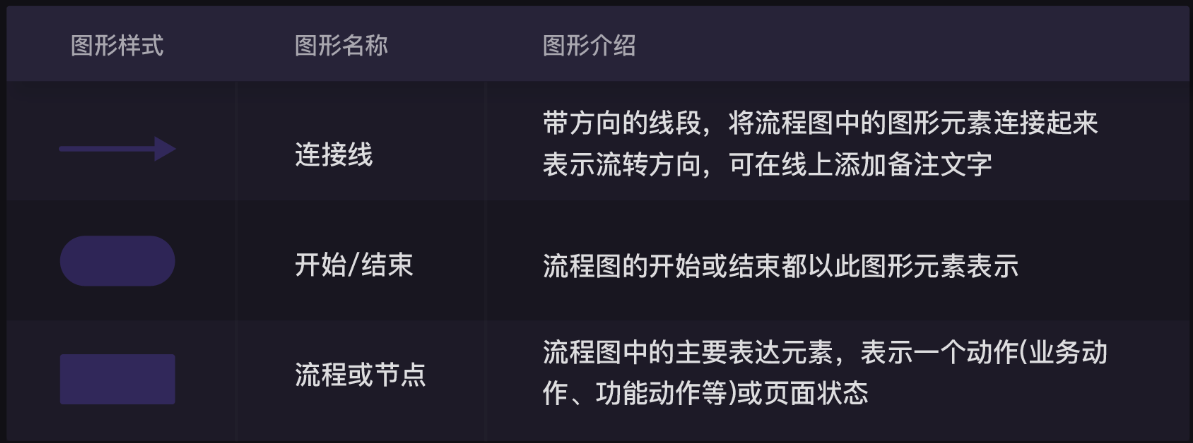

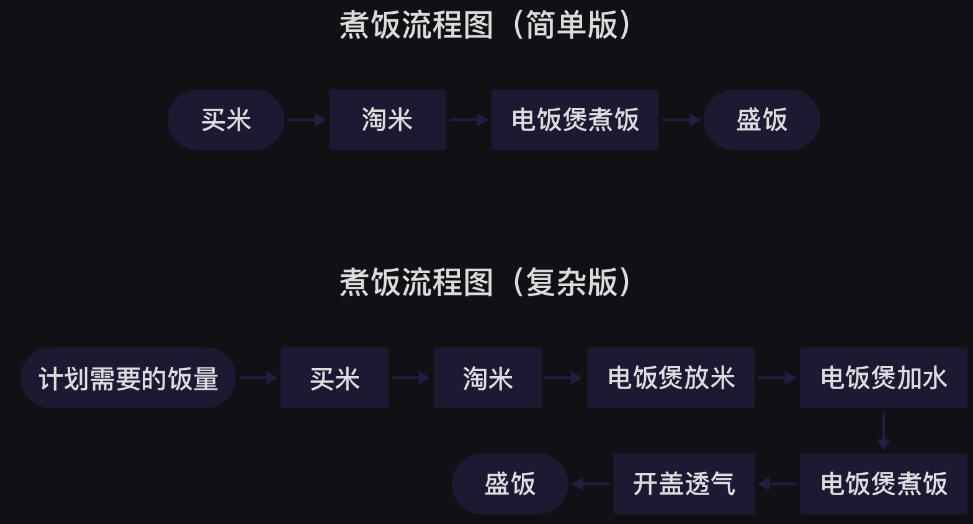
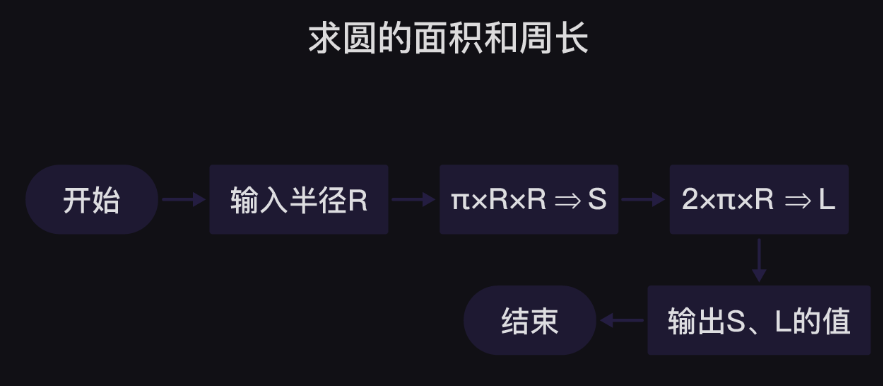
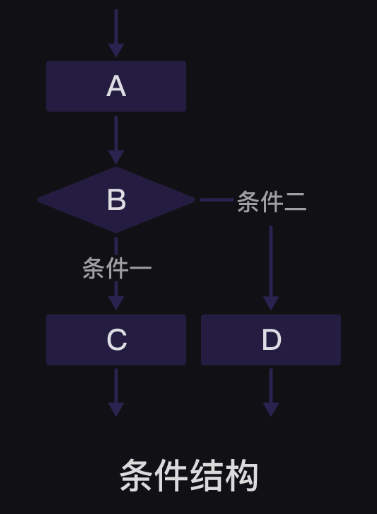

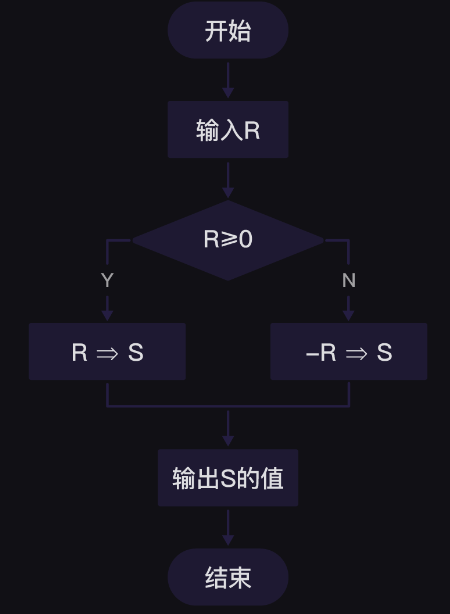
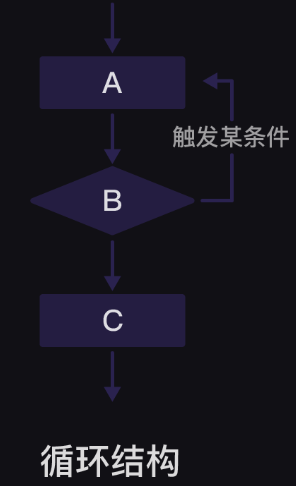
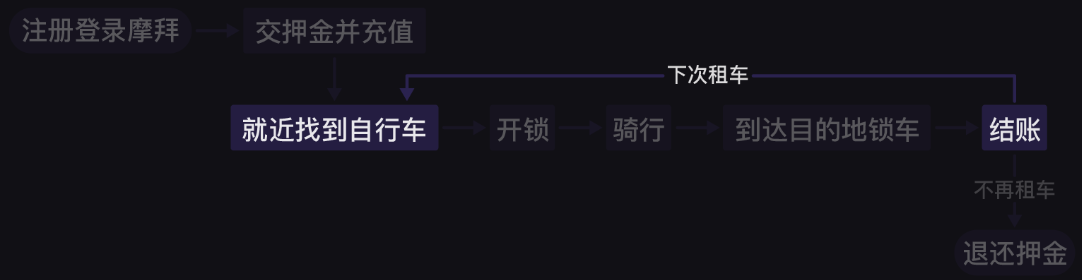
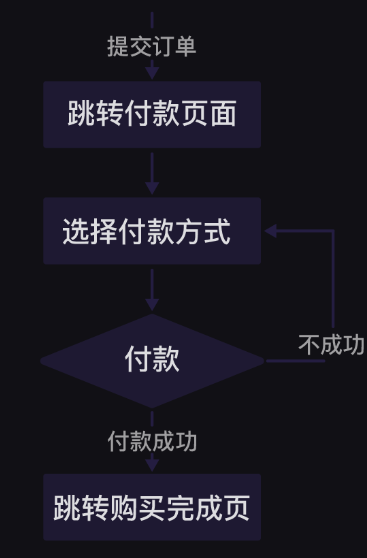
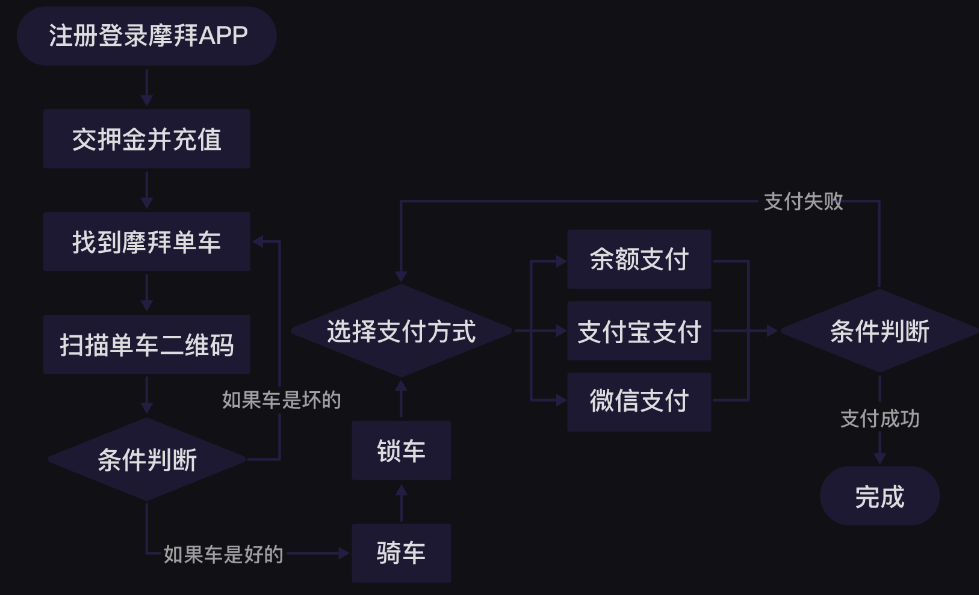
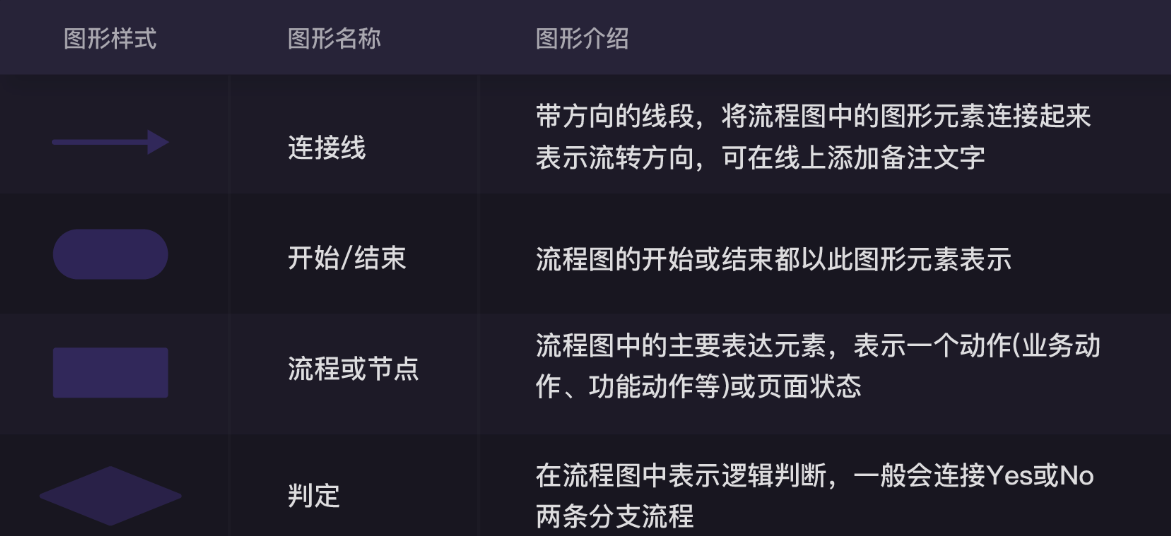
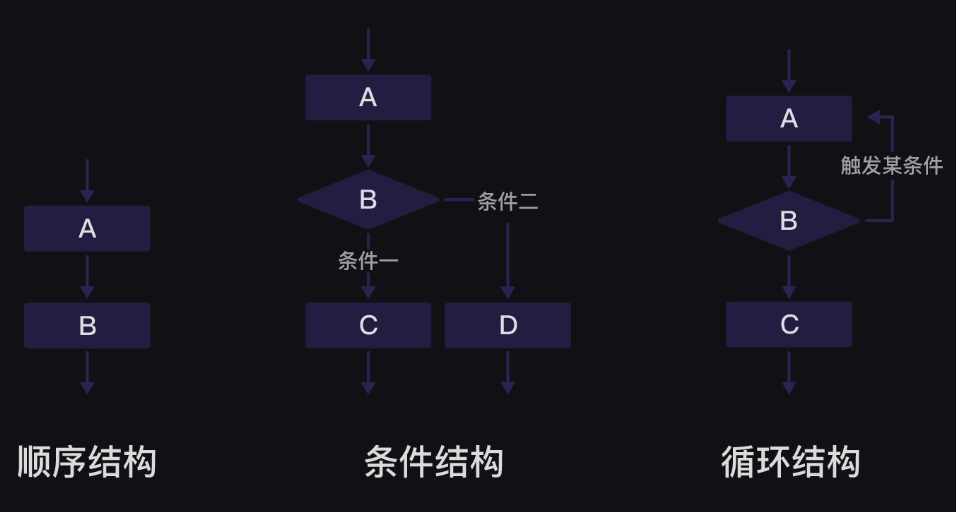




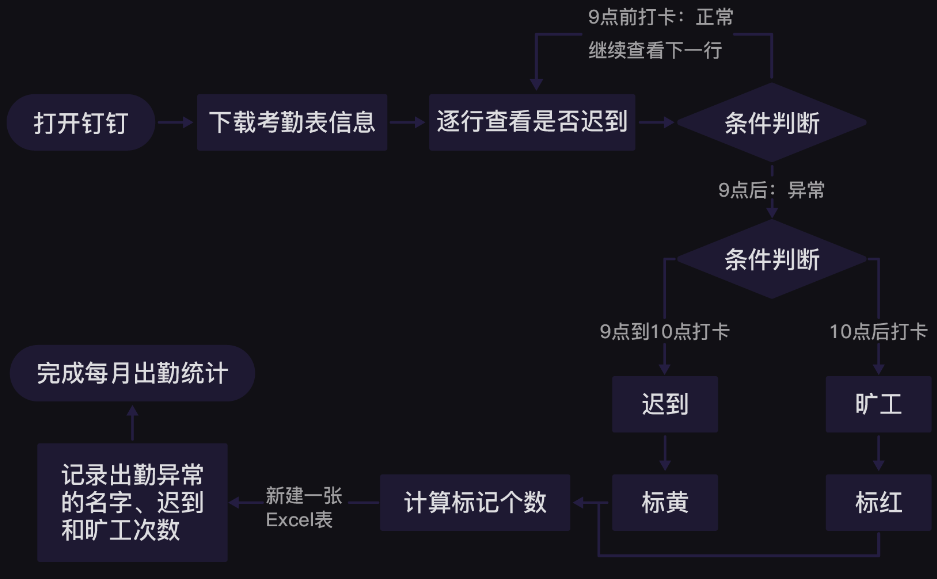
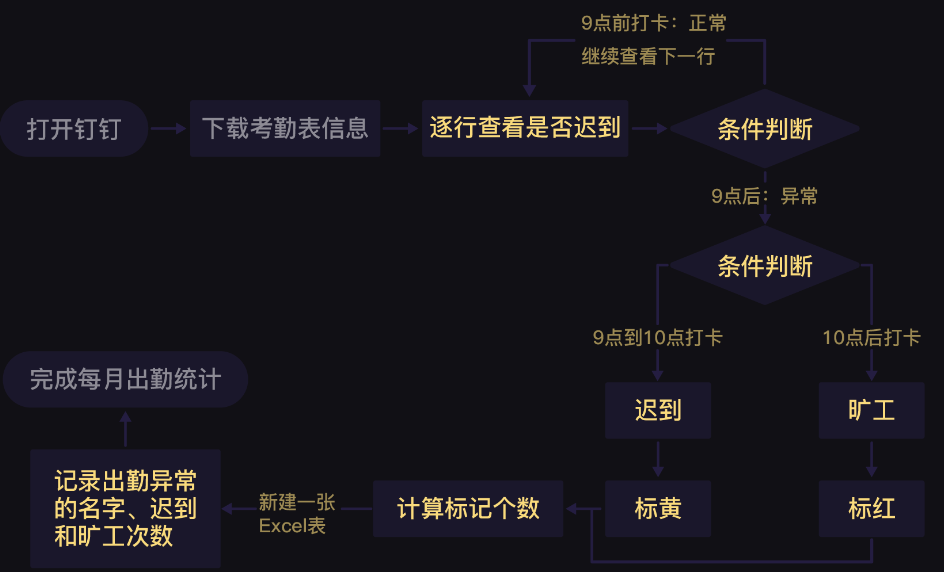
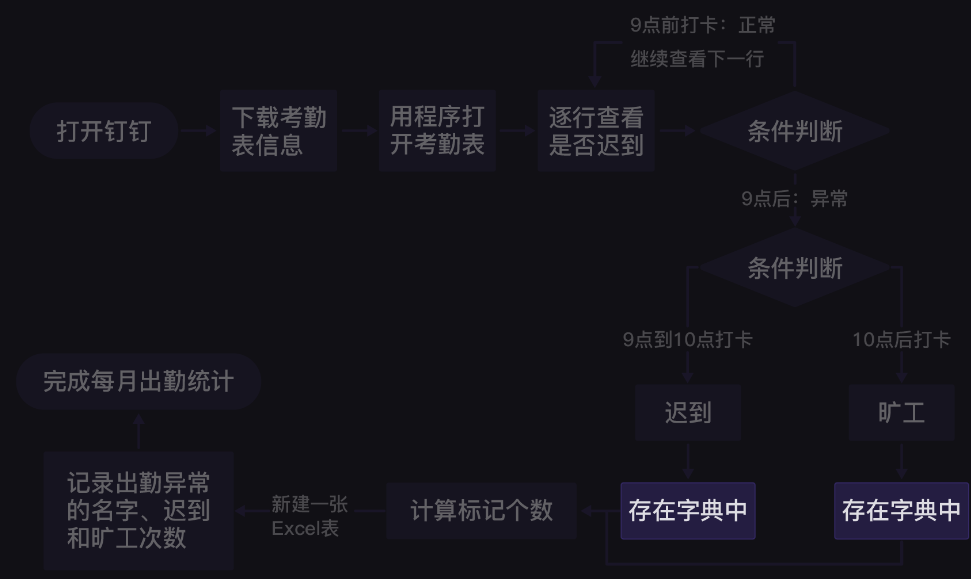




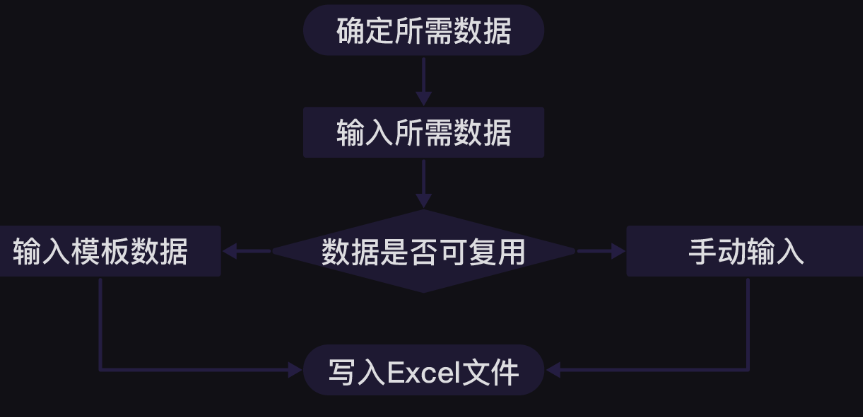


 微信
微信 支付宝
支付宝