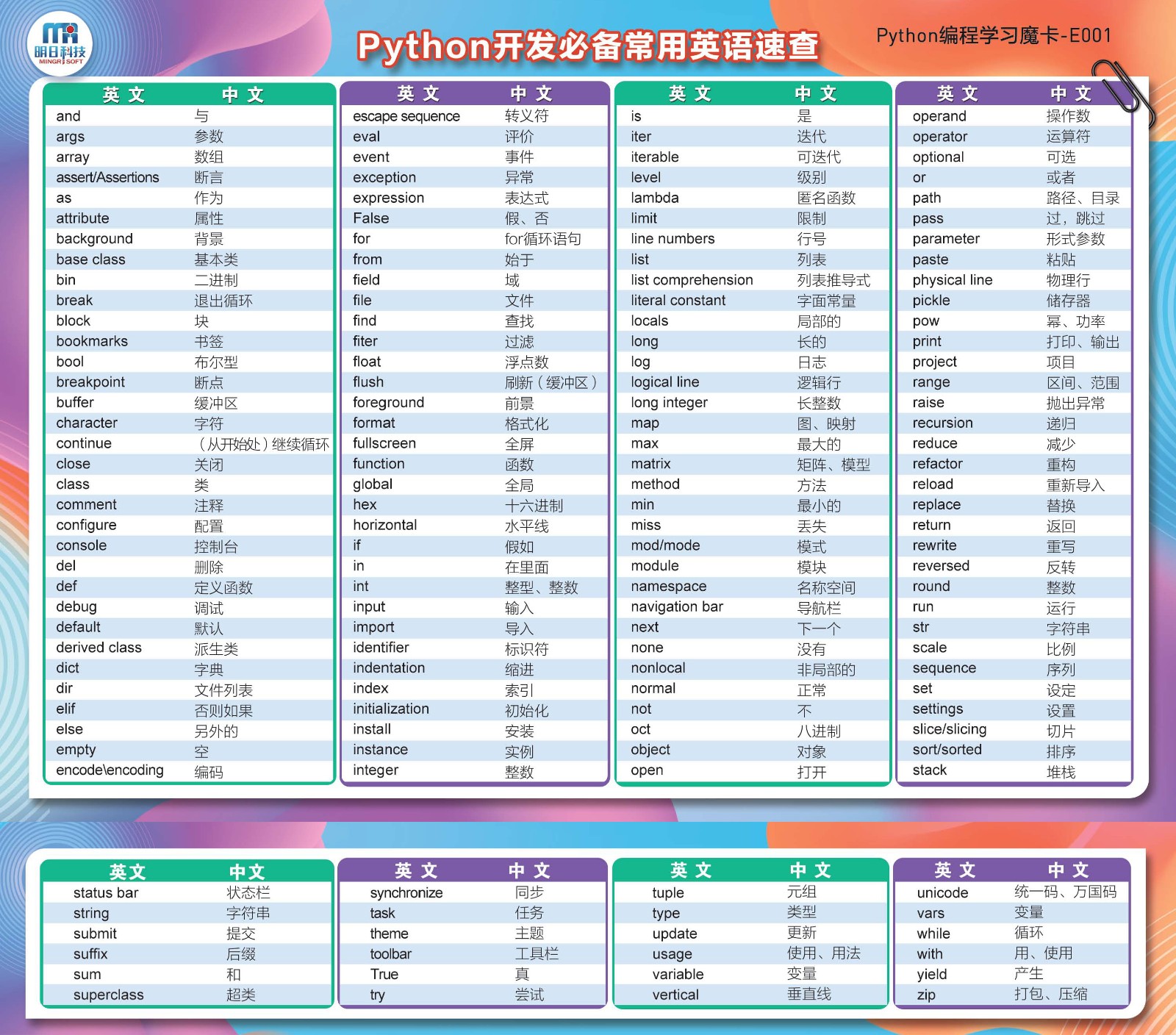
https://www.selenium.dev/documentation/
一、入门指南 1、安装类库 您需要为自动化项目安装 Selenium 绑定库。
2、安装驱动 2.1、安装谷歌浏览器驱动 下载链接 ChromeDriver
2.2、使用驱动的三种方式 2.2.1、驱动管理软件自动更新 2.2.1.1、自动安装对应chrome版本的Webdriver 1 pip install webdriver-manager
2.2.1.2、使用install()获取管理器使用的位置, 并将其传递到服务类中 1 service = Service(executable_path=ChromeDriverManager().install())
2.2.1.3、使用 Service 实例并初始化驱动程序 1 driver = webdriver.Chrome(service=service)
2.2.2、PATH环境变量 您可以将驱动程序放置在路径中已列出的目录中, 也可以将其放置在目录中并将其添加到PATH.
要查看PATH上已经有哪些目录, 请打开命令提示符并执行:
如果驱动程序的位置不在列出的目录中, 可以将新目录添加到PATH:
1 setx PATH "%PATH%;C:\WebDriver\bin"
您可以通过启动驱动程序来测试其是否被正确添加:
2.2.3、硬编码位置(报错) 1 2 3 4 options = EdgeOptions() driver = webdriver.Edge(options=options) driver.quit()
3、打开浏览器 1 2 3 4 from selenium import webdriverdrive = webdriver.Chrome() drive.get('https://www.1688.com/' ) drive.quit()
4、第一个脚本 八个基本组成部分
4.1、使用驱动实例开启会话 1 driver = webdriver.Chrome(service=ChromeService(executable_path=ChromeDriverManager().install()))
4.2、 在浏览器上执行操作 1 driver.get("https://www.selenium.dev/selenium/web/web-form.html" )
4.3、 请求浏览器信息 4.4、 建立等待策略 基本上, 您希望在尝试定位元素之前, 确保该元素位于页面上, 并且在尝试与该元素交互之前, 该元素处于可交互状态.
隐式等待很少是最好的解决方案, 但在这里最容易演示, 所以我们将使用它作为占位符.
1 driver.implicitly_wait(0.5 )
4.5、发送命令查找元素 1 2 text_box = driver.find_element(by=By.NAME, value="my-text" ) submit_button = driver.find_element(by=By.CSS_SELECTOR, value="button" )
4.6、操作元素 1 2 text_box.send_keys("Selenium" ) submit_button.click()
4.7、获取元素信息 4.8、结束会话 这将结束驱动程序进程, 默认情况下, 该进程也会关闭浏览器.
4.9、组合所有事情 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.chrome.service import Service as ChromeServicefrom webdriver_manager.chrome import ChromeDriverManagerdef test_eight_components (): driver = webdriver.Chrome(service=ChromeService(executable_path=ChromeDriverManager().install())) driver.get("https://www.selenium.dev/selenium/web/web-form.html" ) title = driver.title assert title == "Web form" driver.implicitly_wait(0.5 ) text_box = driver.find_element(by=By.NAME, value="my-text" ) submit_button = driver.find_element(by=By.CSS_SELECTOR, value="button" ) text_box.send_keys("Selenium" ) submit_button.click() message = driver.find_element(by=By.ID, value="message" ) value = message.text assert value == "Received!" driver.quit()
5、升级到最新版本 1 pip install selenium==4.4 .3
二、浏览器 1、获取浏览器信息 1.1、获取标题 1.2、获取当前 URL 2、浏览器导航 2.1、打开网站 1 driver.get("https://selenium.dev" )
2.2、后退 2.3、前进 2.4、刷新 3、JavaScript 警告框,提示框和确认框 3.1、Alerts 警告框 1 2 3 4 5 6 7 8 9 10 11 driver.find_element(By.LINK_TEXT, "See an example alert" ).click() alert = wait.until(expected_conditions.alert_is_present()) text = alert.text alert.accept()
3.2、Confirm 确认框 1 2 3 4 5 6 7 8 9 10 11 12 13 14 driver.find_element(By.LINK_TEXT, "See a sample confirm" ).click() wait.until(expected_conditions.alert_is_present()) alert = driver.switch_to.alert text = alert.text alert.dismiss()
3.3、Prompt 提示框 1 2 3 4 5 6 7 8 9 10 11 12 13 14 driver.find_element(By.LINK_TEXT, "See a sample prompt" ).click() wait.until(expected_conditions.alert_is_present()) alert = Alert(driver) alert.send_keys("Selenium" ) alert.accept()
4、同cookies一起工作 4.1、添加cookies 1 2 3 4 5 6 7 8 from selenium import webdriverdriver = webdriver.Chrome() driver.get("http://www.example.com" ) driver.add_cookie({"name" : "key" , "value" : "value" })
4.2、获取命名的 Cookie 1 2 3 4 5 6 7 8 9 10 11 12 from selenium import webdriverdriver = webdriver.Chrome() driver.get("http://www.example.com" ) driver.add_cookie({"name" : "foo" , "value" : "bar" }) print (driver.get_cookie("foo" ))
4.3、获取全部 Cookies 1 2 3 4 5 6 7 8 9 10 11 12 from selenium import webdriverdriver = webdriver.Chrome() driver.get("http://www.example.com" ) driver.add_cookie({"name" : "test1" , "value" : "cookie1" }) driver.add_cookie({"name" : "test2" , "value" : "cookie2" }) print (driver.get_cookies())
4.4、删除 Cookie 1 2 3 4 5 6 7 8 9 10 from selenium import webdriverdriver = webdriver.Chrome() driver.get("http://www.example.com" ) driver.add_cookie({"name" : "test1" , "value" : "cookie1" }) driver.add_cookie({"name" : "test2" , "value" : "cookie2" }) driver.delete_cookie("test1" )
4.5、删除所有 Cookies 1 2 3 4 5 6 7 8 9 10 from selenium import webdriverdriver = webdriver.Chrome() driver.get("http://www.example.com" ) driver.add_cookie({"name" : "test1" , "value" : "cookie1" }) driver.add_cookie({"name" : "test2" , "value" : "cookie2" }) driver.delete_all_cookies()
4.6、Same-Site Cookie属性 此属性允许用户引导浏览器控制cookie, 是否与第三方站点发起的请求一起发送. 引入其是为了防止CSRF(跨站请求伪造)攻击.
Same-Site cookie属性接受以下两种参数作为指令
Strict: 当sameSite属性设置为 Strict , cookie不会与来自第三方网站的请求一起发送.
Lax: 当您将cookie sameSite属性设置为 Lax , cookie将与第三方网站发起的GET请求一起发送.
1 2 3 4 5 6 7 8 9 10 11 12 from selenium import webdriverdriver = webdriver.Chrome() driver.get("http://www.example.com" ) driver.add_cookie({"name" : "foo" , "value" : "value" , 'sameSite' : 'Strict' }) driver.add_cookie({"name" : "foo1" , "value" : "value" , 'sameSite' : 'Lax' }) cookie1 = driver.get_cookie('foo' ) cookie2 = driver.get_cookie('foo1' ) print (cookie1)print (cookie2)
5、与iFrames和frames一起工作 框架是一种现在已被弃用的方法,用于从同一域中的多个文档构建站点布局。除非你使用的是 HTML5 之前的 webapp,否则你不太可能与他们合作。内嵌框架允许插入来自完全不同领域的文档,并且仍然经常使用。
如果您需要使用框架或 iframe, WebDriver 允许您以相同的方式使用它们。考虑 iframe 中的一个按钮。 如果我们使用浏览器开发工具检查元素,我们可能会看到以下内容:
1 2 3 4 5 <div id ="modal" > <iframe id ="buttonframe" name="myframe" src="https://seleniumhq.github.io" > <button>Click here</button> </iframe> </div>
如果不是 iframe,我们可能会使用如下方式点击按钮:
1 2 driver.find_element(By.TAG_NAME, 'button' ).click()
5.1、使用 WebElement 1 2 3 4 5 6 7 8 iframe = driver.find_element(By.CSS_SELECTOR, "#modal > iframe" ) driver.switch_to.frame(iframe) driver.find_element(By.TAG_NAME, 'button' ).click()
5.2、使用 name 或 id 1 2 3 4 5 driver.switch_to.frame('buttonframe' ) driver.find_element(By.TAG_NAME, 'button' ).click()
5.3、使用索引 1 2 3 4 5 iframe = driver.find_elements(By.TAG_NAME,'iframe' )[1 ] driver.switch_to.frame(iframe)
5.4、离开框架 1 2 driver.switch_to.default_content()
6、同窗口和标签一起工作 6.1、窗口和标签页 1 driver.current_window_handle
6.1.1、切换窗口或标签页 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from selenium import webdriverfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as EC with webdriver.Firefox() as driver: driver.get("https://seleniumhq.github.io" ) wait = WebDriverWait(driver, 10 ) original_window = driver.current_window_handle assert len (driver.window_handles) == 1 driver.find_element(By.LINK_TEXT, "new window" ).click() wait.until(EC.number_of_windows_to_be(2 )) for window_handle in driver.window_handles: if window_handle != original_window: driver.switch_to.window(window_handle) break wait.until(EC.title_is("SeleniumHQ Browser Automation" ))
6.1.2、创建新窗口(或)新标签页并且切换 1 2 3 4 5 driver.switch_to.new_window('tab' ) driver.switch_to.new_window('window' )
6.1.3、关闭窗口或标签页 1 2 3 4 5 driver.close() driver.switch_to.window(original_window)
6.1.4、在会话结束时退出浏览器 有的测试框架提供了一些方法和注释,您可以在测试结束时放入 teardown() 方法中。
1 2 3 4 def tearDown (self ):self.driver.quit()
如果不在测试上下文中运行 WebDriver,您可以考虑使用 try / finally,这是大多数语言都提供的, 这样一个异常处理仍然可以清理 WebDriver 会话。
1 2 3 4 try : finally :driver.quit()
Python 的 WebDriver 现在支持 Python 上下文管理器,当使用 with 关键字时,可以在执行结束时自动退出驱动程序。
1 2 3 4 with webdriver.Firefox() as driver:
6.2、窗口管理 6.2.1、获取窗口大小 1 2 3 4 5 6 7 8 width = driver.get_window_size().get("width" ) height = driver.get_window_size().get("height" ) size = driver.get_window_size() width1 = size.get("width" ) height1 = size.get("height" )
6.2.2、设置窗口大小 1 driver.set_window_size(1024 , 768 )
6.2.3、得到窗口的位置 1 2 3 4 5 6 7 8 x = driver.get_window_position().get('x' ) y = driver.get_window_position().get('y' ) position = driver.get_window_position() x1 = position.get('x' ) y1 = position.get('y' )
6.3、设置窗口位置 将窗口移动到设定的位置。
1 2 driver.set_window_position(0 , 0 )
6.3.1、最大化窗口 1 driver.maximize_window()
6.3.2、最小化窗口 1 driver.minimize_window()
6.3.3、全屏窗口 1 driver.fullscreen_window()
6.3.4、屏幕截图 1 2 3 4 5 6 7 8 9 10 11 from selenium import webdriverdriver = webdriver.Chrome() driver.get("http://www.example.com" ) driver.save_screenshot('./image.png' ) driver.quit()
6.3.5、元素屏幕截图 1 2 3 4 5 6 7 8 9 10 11 12 13 14 from selenium import webdriverfrom selenium.webdriver.common.by import Bydriver = webdriver.Chrome() driver.get("http://www.example.com" ) ele = driver.find_element(By.CSS_SELECTOR, 'h1' ) ele.screenshot('./image.png' ) driver.quit()
6.3.6、执行脚本 1 2 3 4 5 header = driver.find_element(By.CSS_SELECTOR, "h1" ) driver.execute_script('return arguments[0].innerText' , header)
6.3.7、打印页面 1 2 3 4 5 6 7 8 from selenium.webdriver.common.print_page_options import PrintOptions print_options = PrintOptions() print_options.page_ranges = ['1-2' ] driver.get("printPage.html" ) base64code = driver.print_page(print_options)
三、元素 1、查询网络元素 HTML 片段
1 2 3 4 5 6 7 8 9 10 <ol id ="vegetables" > <li class ="potatoes" >… <li class ="onions" >… <li class ="tomatoes" ><span>Tomato is a Vegetable</span>… </ol> <ul id ="fruits" > <li class ="bananas" >… <li class ="apples" >… <li class ="tomatoes" ><span>Tomato is a Fruit</span>… </ul>
1.1、第一个匹配元素 1.1.1、评估整个 DOM 当在驱动程序实例上调用 find element 方法时,它返回对 DOM 中与提供的定位器匹配的第一个元素的引用。该值可以存储并用于将来的元素操作。在我们上面的示例 HTML 中,有两个元素的类名为“tomatoes”,因此此方法将返回“vegetables”列表中的元素。
1 vegetable = driver.find_element(By.CLASS_NAME, "tomatoes" )
1.1.2、评估 DOM 的子集 与其在整个 DOM 中找到唯一的定位器,不如将搜索范围缩小到另一个定位元素的范围通常很有用。在上面的示例中,有两个元素的类名为“tomatoes”,要获得第二个的引用更具挑战性。
一种解决方案是找到具有唯一属性的元素,该属性是所需元素的祖先而不是不需要元素的祖先,然后在该对象上调用 find 元素:
1 2 fruits = driver.find_element(By.ID, "fruits" ) fruit = fruits.find_element(By.CLASS_NAME,"tomatoes" )
1.1.3、优化定位器 嵌套查找可能不是最有效的定位策略,因为它需要向浏览器发出两个单独的命令。
为了稍微提高性能,我们可以使用 CSS 或 XPath 在单个命令中查找此元素。
1 fruit = driver.find_element(By.CSS_SELECTOR,"#fruits .tomatoes" )
1.2、所有匹配元素 1 plants = driver.find_elements(By.TAG_NAME, "li" )
1.2.1、获取元素 1 2 3 4 5 6 7 8 9 10 11 12 13 from selenium import webdriverfrom selenium.webdriver.common.by import Bydriver = webdriver.Firefox() driver.get("https://www.example.com" ) elements = driver.find_elements(By.TAG_NAME, 'p' ) for e in elements: print (e.text)
1.3、从元素中查找元素 1 2 3 4 5 6 7 8 9 10 11 12 13 from selenium import webdriverfrom selenium.webdriver.common.by import Bydriver = webdriver.Chrome() driver.get("https://www.example.com" ) element = driver.find_element(By.TAG_NAME, 'div' ) elements = element.find_elements(By.TAG_NAME, 'p' ) for e in elements: print (e.text)
1.4、获取活动元素 1 2 3 4 5 6 7 8 9 10 from selenium import webdriverfrom selenium.webdriver.common.by import Bydriver = webdriver.Chrome() driver.get("https://www.google.com" ) driver.find_element(By.CSS_SELECTOR, '[name="q"]' ).send_keys("webElement" ) attr = driver.switch_to.active_element.get_attribute("title" ) print (attr)
2、Web元素交互 2.1、附加验证 这些方法的设计目的是尽量模拟用户体验, 所以, 与 Actions接口 不同, 在指定制定操作之前, 会尝试执行两件事.
如果它确定元素在视口之外, 则会将元素滚动到视图中 , 特别是将元素底部与视口底部对齐.
确保元素在执行操作之前是可交互的 . 这可能意味着滚动不成功, 或者该元素没有以其他方式显示.无法直接在webdriver规范中定义 , 因此Selenium发送一个带有JavaScript原子的执行命令, 检查是否有可能阻止该元素显示. 如果确定某个元素不在视口中, 不显示, 不可 键盘交互 , 或不可 指针交互 , 则返回一个元素不可交互 错误。
2.2、点击 元素点击命令 执行在 元素中央 . 如果元素中央由于某些原因被 遮挡 , Selenium将返回一个 元素点击中断 错误。
2.3、发送键位 元素发送键位命令 将录入提供的键位到 可编辑的 元素. 通常, 这意味着元素是具有 文本 类型的表单的输入元素或具有 内容可编辑 属性的元素. 如果不可编辑, 则返回 无效元素状态 错误。
1 2 3 4 5 6 7 8 9 10 from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.common.keys import Keysdriver = webdriver.Firefox() driver.get("http://www.google.com" ) driver.find_element(By.NAME, "q" ).send_keys("webdriver" + Keys.ENTER)
2.4、清除 1 2 3 4 5 6 7 8 9 10 11 from selenium import webdriverfrom selenium.webdriver.common.by import Bydriver = webdriver.Chrome() driver.get("http://www.google.com" ) SearchInput = driver.find_element(By.NAME, "q" ) SearchInput.send_keys("selenium" ) SearchInput.clear()
2.5、提交 在Selenium 4中, 不再通过单独的端点以及脚本执行的方法来实现. 因此, 建议不要使用此方法, 而是单击相应的表单提交按钮。
3、定位策略 3.1、元素选择策略
定位器 Locator
描述
class name
定位class属性与搜索值匹配的元素(不允许使用复合类名)
css selector
定位 CSS 选择器匹配的元素
id
定位 id 属性与搜索值匹配的元素
name
定位 name 属性与搜索值匹配的元素
link text
定位link text可视文本与搜索值完全匹配的锚元素
partial link text
定位link text可视文本部分与搜索值部分匹配的锚点元素。如果匹配多个元素,则只选择第一个元素。
tag name
定位标签名称与搜索值匹配的元素
xpath
定位与 XPath 表达式匹配的元素
3.2、相对定位器 3.2.1、这个怎么运作 相对定位器方法可以作为原点的参数,可以是先前定位的元素参考,也可以是另一个定位器。在这些示例中,我们将仅使用定位器,但您可以将 final 方法中的定位器与元素对象交换,它的工作方式相同。
3.2.2、可用的相对定位器 Above 1 email_locator = locate_with(By.TAG_NAME, "input" ).above({By.ID: "password" })
Below 1 password_locator = locate_with(By.TAG_NAME, "input" ).below({By.ID: "email" })
Left of 1 cancel_locator = locate_with(By.TAG_NAME, "button" ).to_left_of({By.ID: "submit" })
Right of 1 submit_locator = locate_with(By.TAG_NAME, "button" ).to_right_of({By.ID: "cancel" })
Near 1 email_locator = locate_with(By.TAG_NAME, "input" ).near({By.ID: "lbl-email" })
3.2.3、链接相对定位器 1 submit_locator = locate_with(By.TAG_NAME, "button" ).below({By.ID: "email" }).to_right_of({By.ID: "cancel" })
4、关于网络元素的信息 4.1、是否显示 1 2 3 4 5 driver.get("https://www.google.com" ) is_button_visible = driver.find_element(By.CSS_SELECTOR, "[name='login']" ).is_displayed()
4.2、元素是否被选定 1 2 3 4 5 driver.get("https://the-internet.herokuapp.com/checkboxes" ) value = driver.find_element(By.CSS_SELECTOR, "input[type='checkbox']:first-of-type" ).is_selected()
4.3、获取元素标签名 1 2 3 4 5 driver.get("https://www.example.com" ) attr = driver.find_element(By.CSS_SELECTOR, "h1" ).tag_name
4.4、获取元素矩形 1 2 3 4 5 driver.get("https://www.example.com" ) res = driver.find_element(By.CSS_SELECTOR, "h1" ).rect
4.5、获取元素CSS值 1 2 3 4 5 driver.get('https://www.example.com' ) cssValue = driver.findElement(By.LINK_TEXT, "More information..." ).value_of_css_property('color' )
4.6、获取元素文本 1 2 3 4 5 driver.get("https://www.example.com" ) text = driver.find_element(By.CSS_SELECTOR, "h1" ).text
4.7、特性和属性 4.7.1、特性 4.7.2、DOM 特性 4.7.3、DOM 属性 5、使用选择列表元素 选择元素可能需要大量样板代码才能自动化. 为了减少这种情况并使您的测试更干净, 在Selenium的support包中有一个 Select 类. 要使用它,您将需要以下导入语句:
1 from selenium.webdriver.support.select import Select
然后,您能够参考 <select> 元素,基于WebElement创建一个Select对象。
1 2 select_element = driver.find_element(By.ID,'selectElementID' ) select_object = Select(select_element)
Select对象现在将为您提供一系列命令,使您可以与 <select> 元素进行交互. 首先,有多种方法可以从 <select> 元素中选择一个选项。
1 2 3 4 5 <select > <option value =value1 > Bread</option > <option value =value2 selected > Milk</option > <option value =value3 > Cheese</option > </select >
有三种方法可以从上述元素中选择第一个选项:
1 2 3 4 5 6 7 8 select_object.select_by_index(1 ) select_object.select_by_value('value1' ) select_object.select_by_visible_text('Bread' )
然后,您可以检视所有被选择的选项:
1 2 3 4 5 all_selected_options = select_object.all_selected_options first_selected_option = select_object.first_selected_option
或者您可能只对 <select> 元素包含哪些 <option> 元素感兴趣:
1 2 all_available_options = select_object.options
如果要取消选择任何元素,现在有四个选项:
1 2 3 4 5 6 7 8 9 10 11 select_object.deselect_by_index(1 ) select_object.deselect_by_value('value1' ) select_object.deselect_by_visible_text('Bread' ) select_object.deselect_all()
最后,一些 <select> 元素允许您选择多个选项. 您可以通过使用以下命令确定您的 <select> 元素是否允许多选:
1 does_this_allow_multiple_selections = select_object.is_multiple
四、远程WebDriver 您可以如本地一样, 使用远程WebDriver. 主要区别在于需要配置远程WebDriver, 以便可以在不同的计算机上运行测试.
远程WebDriver由两部分组成:客户端和服务端. 客户端是您的WebDriver测试,而服务端仅仅是可以被托管于任何现代Java EE应用服务器的Java Servlet.
要运行远程WebDriver客户端, 我们首先需要连接到RemoteWebDriver. 为此, 我们将URL指向运行测试的服务器的地址. 为了自定义我们的配置, 我们设置了既定的功能. 下面是一个实例化样例, 其指向我们的远程Web服务器 www.example.com
1 2 3 4 5 6 7 8 9 from selenium import webdriverfirefox_options = webdriver.FirefoxOptions() driver = webdriver.Remote( command_executor='http://www.example.com' , options=firefox_options ) driver.get("http://www.google.com" ) driver.quit()
4.1、浏览器选项 假设您想使用Chrome版本67 在Windows XP上运行Chrome:
1 2 3 4 5 6 7 8 9 10 11 from selenium import webdriverchrome_options = webdriver.ChromeOptions() chrome_options.set_capability("browserVersion" , "67" ) chrome_options.set_capability("platformName" , "Windows XP" ) driver = webdriver.Remote( command_executor='http://www.example.com' , options=chrome_options ) driver.get("http://www.google.com" ) driver.quit()
4.2、本地文件检测器 本地文件检测器允许将文件从客户端计算机传输到远程服务器. 例如, 如果测试需要将文件上传到Web应用程序, 则远程WebDriver可以在运行时 将文件从本地计算机自动传输到远程Web服务器. 这允许从运行测试的远程计算机上载文件. 默认情况下未启用它, 可以通过以下方式启用
1 2 3 from selenium.webdriver.remote.file_detector import LocalFileDetectordriver.file_detector = LocalFileDetector()
定义上述代码后, 您可以通过以下方式在测试中上传文件。
1 2 3 driver.get("http://sso.dev.saucelabs.com/test/guinea-file-upload" ) driver.find_element(By.ID, "myfile" ).send_keys("/Users/sso/the/local/path/to/darkbulb.jpg" )
五、等待 WebDriver通常可以说有一个阻塞API。因为它是一个指示浏览器做什么的进程外库,而且web平台本质上是异步的,所以WebDriver不跟踪DOM的实时活动状态。这伴随着一些我们将在这里讨论的挑战。
根据经验,大多数由于使用Selenium和WebDriver而产生的间歇性问题都与浏览器和用户指令之间的 竞争条件 有关。例如,用户指示浏览器导航到一个页面,然后在试图查找元素时得到一个 no such element 的错误。
考虑下面的文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <!doctype html > <meta charset =utf-8 > <title > Race Condition Example</title > <script > var initialised = false ; window .addEventListener ("load" , function ( var newElement = document .createElement ("p" ); newElement.textContent = "Hello from JavaScript!" ; document .body .appendChild (newElement); initialised = true ; }); </script >
这个 WebDriver的说明可能看起来很简单:
1 2 3 driver.navigate("file:///race_condition.html" ) el = driver.find_element(By.TAG_NAME, "p" ) assert el.text == "Hello from JavaScript!"
这里的问题是WebDriver中使用的默认页面加载策略页面加载策略 听从document.readyState在返回调用 navigate 之前将状态改为"complete" 。因为p元素是在文档完成加载之后添加的,所以这个WebDriver脚本可能是间歇性的。它“可能”间歇性是因为无法做出保证说异步触发这些元素或事件不需要显式等待或阻塞这些事件。
幸运的是,WebElement WebElement.click 和 WebElement.sendKeys —是保证同步的,因为直到命令在浏览器中被完成之前函数调用是不会返回的(或者回调是不会在回调形式的语言中触发的)。高级用户交互APIs,键盘 鼠标
等待是在继续下一步之前会执行一个自动化任务来消耗一定的时间。
为了克服浏览器和WebDriver脚本之间的竞争问题,大多数Selenium客户都附带了一个 wait 包。在使用等待时,您使用的是通常所说的显式等待
5.1、显式等待 显示等待 是Selenium客户可以使用的命令式过程语言。它们允许您的代码暂停程序执行,或冻结线程,直到满足通过的 条件 。这个条件会以一定的频率一直被调用,直到等待超时。这意味着只要条件返回一个假值,它就会一直尝试和等待
由于显式等待允许您等待条件的发生,所以它们非常适合在浏览器及其DOM和WebDriver脚本之间同步状态。
为了弥补我们之前的错误指令集,我们可以使用等待来让 findElement 调用等待直到脚本中动态添加的元素被添加到DOM中。
1 2 3 4 5 6 7 8 from selenium.webdriver.support.wait import WebDriverWaitdef document_initialised (driver ): return driver.execute_script("return initialised" ) driver.navigate("file:///race_condition.html" ) WebDriverWait(driver, timeout=10 ).until(document_initialised) el = driver.find_element(By.TAG_NAME, "p" ) assert el.text == "Hello from JavaScript!"
我们将 条件 作为函数引用传递, 等待 将会重复运行直到其返回值为true。“truthful”返回值是在当前语言中计算为boolean true的任何值,例如字符串、数字、boolean、对象(包括 WebElement )或填充(非空)的序列或列表。这意味着 空列表 的计算结果为false。当条件为true且阻塞等待终止时,条件的返回值将成为等待的返回值。
有了这些知识,并且因为等待实用程序默认情况下会忽略 no such element 的错误,所以我们可以重构我们的指令使其更简洁。
1 2 3 4 5 from selenium.webdriver.support.wait import WebDriverWaitdriver.navigate("file:///race_condition.html" ) el = WebDriverWait(driver, timeout=3 ).until(lambda d: d.find_element(By.TAG_NAME,"p" )) assert el.text == "Hello from JavaScript!"
在这个示例中,我们传递了一个匿名函数(但是我们也可以像前面那样显式地定义它,以便重用它)。传递给我们条件的第一个,也是唯一的一个参数始终是对驱动程序对象 WebDriver 的引用。在多线程环境中,您应该小心操作传入条件的驱动程序引用,而不是外部范围中对驱动程序的引用。
因为等待将会吞没在没有找到元素时引发的 no such element 的错误,这个条件会一直重试直到找到元素为止。然后它将获取一个 WebElement 的返回值,并将其传递回我们的脚本。
如果条件失败,例如从未得到条件为真实的返回值,等待将会抛出/引发一个叫 timeout error 的错误/异常。
5.1.1、选项 等待条件可以根据您的需要进行定制。有时候是没有必要等待缺省超时的全部范围,因为没有达到成功条件的代价可能很高。
等待允许你传入一个参数来覆盖超时:
1 WebDriverWait(driver, timeout=3 ).until(some_condition)
5.1.2、预期的条件 由于必须同步DOM和指令是相当常见的情况,所以大多数客户端还附带一组预定义的 预期条件 。顾名思义,它们是为频繁等待操作预定义的条件。
不同的语言绑定提供的条件各不相同,但这只是其中一些:
alert is present
element exists
element is visible
title contains
title is
element staleness
visible text
您可以参考每个客户端绑定的API文档,以找到期望条件的详尽列表:
5.2、隐式等待 还有第二种区别于显示等待 类型的 隐式等待 。通过隐式等待,WebDriver在试图查找_任何_元素时在一定时间内轮询DOM。当网页上的某些元素不是立即可用并且需要一些时间来加载时是很有用的。
默认情况下隐式等待元素出现是禁用的,它需要在单个会话的基础上手动启用。将显式等待 和隐式等待混合在一起会导致意想不到的结果,就是说即使元素可用或条件为真也要等待睡眠的最长时间。
警告: 不要混合使用隐式和显式等待。这样做会导致不可预测的等待时间。例如,将隐式等待设置为10秒,将显式等待设置为15秒,可能会导致在20秒后发生超时。
隐式等待是告诉WebDriver如果在查找一个或多个不是立即可用的元素时轮询DOM一段时间。默认设置为0,表示禁用。一旦设置好,隐式等待就被设置为会话的生命周期。
1 2 3 4 driver = Firefox() driver.implicitly_wait(10 ) driver.get("http://somedomain/url_that_delays_loading" ) my_dynamic_element = driver.find_element(By.ID, "myDynamicElement" )
5.3、流畅等待 流畅等待实例定义了等待条件的最大时间量,以及检查条件的频率。
用户可以配置等待来忽略等待时出现的特定类型的异常,例如在页面上搜索元素时出现的NoSuchElementException。
1 2 3 4 driver = Firefox() driver.get("http://somedomain/url_that_delays_loading" ) wait = WebDriverWait(driver, timeout=10 , poll_frequency=1 , ignored_exceptions=[ElementNotVisibleException, ElementNotSelectableException]) element = wait.until(EC.element_to_be_clickable((By.XPATH, "//div" )))
 微信
微信 支付宝
支付宝